filmov
tv
WTF is MapReduce?? [Batch Processing] | Systems Design Interview 0 to 1 with Ex-Google SWE

Показать описание
I'd post this to Blind but I think they're more in need of FapReduce instead of MapReduce
 0:09:19
0:09:19
WTF is MapReduce?? [Batch Processing] | Systems Design Interview 0 to 1 with Ex-Google SWE
 0:09:09
0:09:09
Map Reduce explained with example | System Design
 0:09:58
0:09:58
What is MapReduce♻️in Hadoop🐘| Apache Hadoop🐘
 0:06:21
0:06:21
Hadoop In 5 Minutes | What Is Hadoop? | Introduction To Hadoop | Hadoop Explained |Simplilearn
 0:06:41
0:06:41
MapReduce - Computerphile
 0:07:00
0:07:00
Map Reduce explained with example | System Design
 0:00:25
0:00:25
0115 big data analysis using map reduce batch processing ppt slide
 0:35:07
0:35:07
What Is MapReduce? | What Is MapReduce In Hadoop? | Hadoop MapReduce Tutorial | Simplilearn
 0:12:30
0:12:30
Google SWE teaches systems design | EP15: Batch Processing
 0:01:19
0:01:19
What is Batch Processing?
 0:02:47
0:02:47
3.10 Enterprise batch processing | CS802(B) |
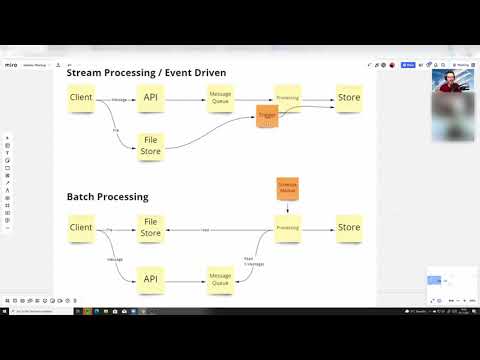 0:09:02
0:09:02
Stream vs Batch processing explained with examples
 0:32:32
0:32:32
Working Process of MapReduce Overview | Distributed Offline Batch Processing and Yarn
 0:16:54
0:16:54
Chapter 10 Batch Processing
 0:00:28
0:00:28
What is MapReduce Function in Bigdata and Hadoop? #mapreduce #bigdata #datascience #dataanalytics
 0:02:05
0:02:05
Advantages of map reduce in Cloud computing | hadoop batch processing
 0:00:49
0:00:49
The MapReduce tldr
 0:09:04
0:09:04
Data - Batch processing vs Stream processing
 0:21:25
0:21:25
What is Batch processing and real-time Processing | Apache Spark Tutorial | Edureka
 0:13:37
0:13:37
Batch Processing vs Stream Processing | System Design Primer | Tech Primers
 0:07:34
0:07:34
Why Spark is Faster Than Hadoop MapReduce
 0:00:15
0:00:15
My Jobs Before I was a Project Manager
 0:10:01
0:10:01
Hadoop vs Spark | Hadoop And Spark Difference | Hadoop And Spark Training | Simplilearn
 0:00:36
0:00:36
3: Spark over MapReduce - Versatility #spark #programming #learning #python #datascience #jeenu #sql
Комментарии