filmov
tv
Gzip is all You Need! (This SHOULD NOT work)

Показать описание
 0:19:47
0:19:47
Gzip is all You Need! (This SHOULD NOT work)
 0:02:18
0:02:18
gzip file compression in 100 Seconds
 0:00:32
0:00:32
gzip is All You Need - Just Use MariaDB!
 0:19:10
0:19:10
How Gzip Compression Works
 0:23:43
0:23:43
Linux by example - Less, gzip, iproute, make and patch
 0:06:07
0:06:07
How to Add HTML Compression /GZIP
 0:02:25
0:02:25
How gzip works
 0:00:20
0:00:20
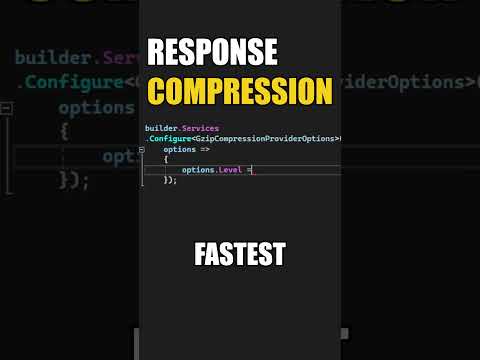
How To Configure Gzip Compression In ASP.NET Core #shorts
 0:59:06
0:59:06
GZIP is not enough!
 0:04:02
0:04:02
GZIP Compression Is A Quick Way To Improve WordPress Site Speed
 0:08:35
0:08:35
GZIP Compression ( Increase Any Website Speed upto 10x )
 0:29:19
0:29:19
From nothin’ to gzip - HTTP 203
 0:06:46
0:06:46
Use Gzip Compression Whenever Possible - Use Gzip in Joomla 🛠Maintenance Monday Live Stream #002 -...
 0:24:20
0:24:20
Raul Fraile: How GZIP compression works | JSConf EU 2014
 0:03:52
0:03:52
How to optimize Page Speed Gzip Compression
 0:07:07
0:07:07
Brotli Compression vs GZIP Compression
 0:07:54
0:07:54
How to Enable GZIP Compression in WordPress
 0:04:00
0:04:00
Linux gzip command summary with examples
 0:03:23
0:03:23
How to Enable GZIP Compression in WordPress (Two Methods) #WordPress
 0:02:11
0:02:11
TIP : Gzip - Windows 10, the easy way
 0:03:49
0:03:49
Leverage Browser Caching and GZIP compression in Wordpress (Easy fix 2021)
 0:06:24
0:06:24
Gzip compression
 0:02:36
0:02:36
How to get Faster Site Speed with Gzip
 0:00:51
0:00:51
HTML : How to decode 'Content-Encoding: gzip, gzip' using curl?
Комментарии