filmov
tv
Understanding Pipeline in Machine Learning with Scikit-learn (sklearn pipeline)
Показать описание
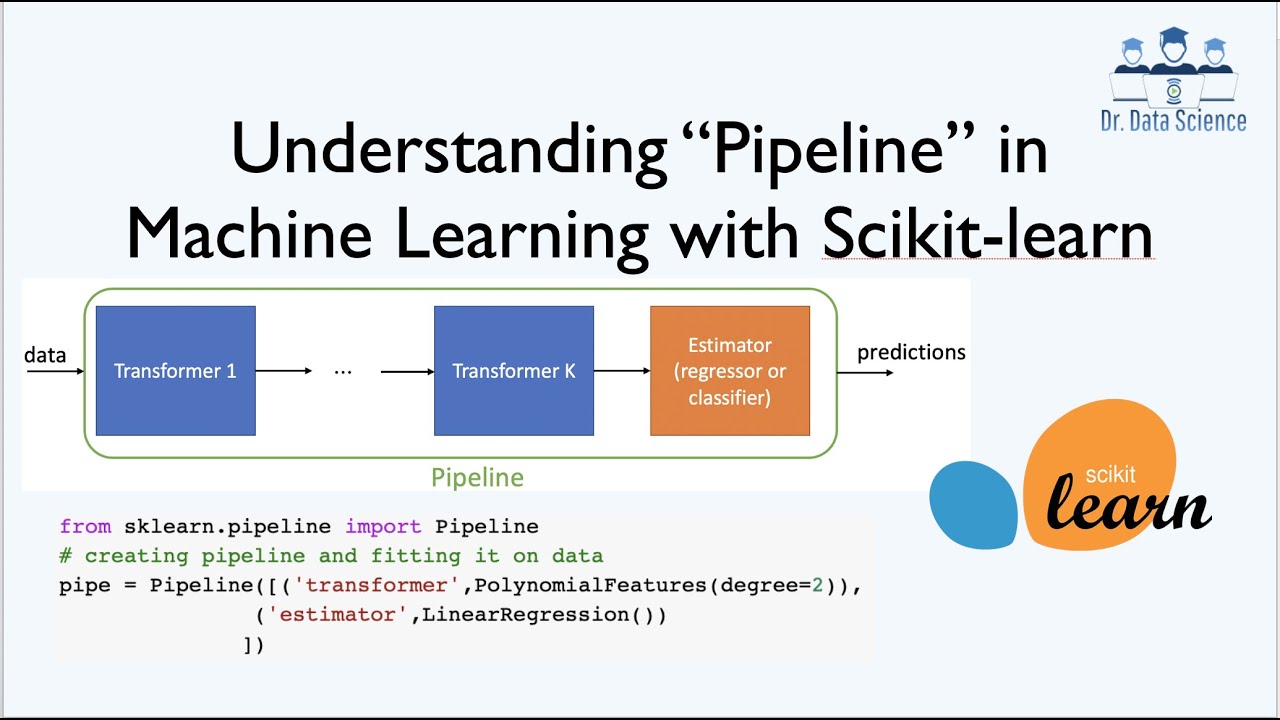
Often in Machine Learning and Data Science, you need to perform a sequence of different transformations of the input data (such as finding a set of features or generating new features) before applying a final estimator. Pipeline gives you a single interface for encapsulating transformers and predictors to simplify the process. Since transformers are usually combined with estimators for preprocessing, using pipeline in scikit-learn can be really useful. To be precise, Pipelines sequentially apply a list of transformers and a final estimator. Therefore, the purpose of the pipeline is to assemble several steps that can be cross-validated while setting different parameters. In this video, we discuss the Python implementation of Pipeline using a polynomial regression example.
#Transformer #Estimator #Pipeline
#Transformer #Estimator #Pipeline
 0:02:42
0:02:42
What Is a Machine Learning Pipeline?
 0:08:18
0:08:18
Pipeline In Machine Learning | How to write pipeline in machine learning
 0:09:07
0:09:07
Understanding Pipeline in Machine Learning with Scikit-learn (sklearn pipeline)
 0:05:25
0:05:25
What is Data Pipeline? | Why Is It So Popular?
 0:21:48
0:21:48
Professional Preprocessing with Pipelines in Python
 0:07:54
0:07:54
Let’s Write a Pipeline - Machine Learning Recipes #4
 0:13:44
0:13:44
MLOps explained | Machine Learning Essentials
 0:10:34
0:10:34
What is Data Pipeline | How to design Data Pipeline ? - ETL vs Data pipeline (2024)
 1:13:05
1:13:05
End to End Machine Learning Project Implementation using AWS Sagemaker
 0:02:03
0:02:03
CI CD Pipeline Explained in 2 minutes With Animation!
 0:03:24
0:03:24
What is the Machine Learning Pipeline?
 0:11:05
0:11:05
Machine Learning Pipeline In Python | How to run pipeline in python machine learning
 0:29:11
0:29:11
Building a Machine Learning Pipeline with Python and Scikit-Learn | Step-by-Step Tutorial
 0:03:18
0:03:18
Machine Learning Pipeline
 0:16:50
0:16:50
Scikit-Learn Model Pipeline Tutorial
 0:11:43
0:11:43
The Data Science Pipeline
 1:05:56
1:05:56
Mastering Machine Learning – Ep.2: Build and Run a Machine Learning Pipeline
 0:08:23
0:08:23
The Machine Learning Pipeline | Kadenze
 0:26:39
0:26:39
Industry Level Machine Learning Project Pipeline | How a machine learning project pipeline is build
 0:09:21
0:09:21
What is ETL Pipeline? | ETL Pipeline Tutorial | How to Build ETL Pipeline | Simplilearn
 0:38:47
0:38:47
Jose Quesada - A full Machine learning pipeline in Scikit-learn vs in scala-Spark: pros and cons
 0:16:43
0:16:43
(Ep #4 - Rasa Masterclass) Training the NLU models: understanding pipeline components | Rasa 1.8.0
 0:09:11
0:09:11
Transformers, explained: Understand the model behind GPT, BERT, and T5
 0:07:26
0:07:26
What is CI/CD Pipeline? (in Layman's terms)
Комментарии