filmov
tv
Realtime Streaming with Apache Flink | End to End Data Engineering Project
Показать описание
In this video, you will be building an end-to-end data engineering project using some of the most powerful technologies in the industry: Apache Flink, Kafka, Elasticsearch, and Docker. In this video, we dive deep into the world of real-time data processing and analytics, guiding you through every step of creating a robust, scalable data pipeline.
Timestamp
0:00 Introduction
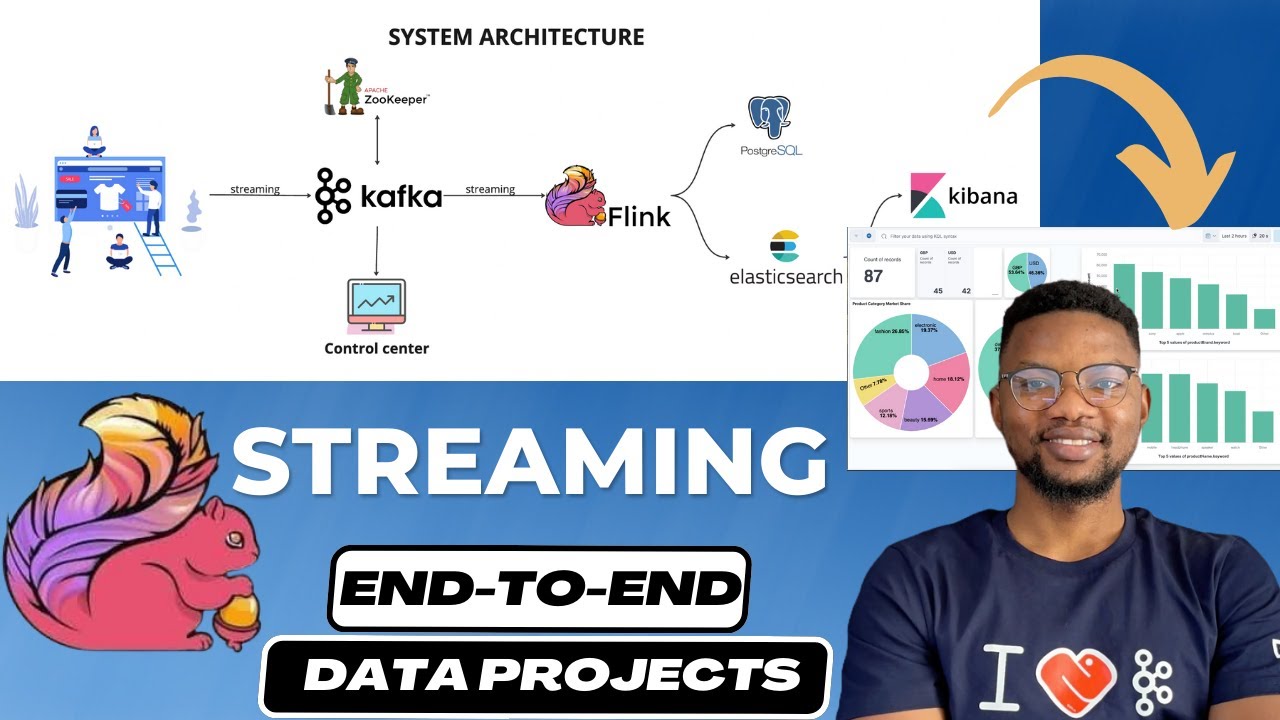
0:55 The system architecture
08:00 Sales Analytics Data Generation
19:10 Producing Data into Kafka Broker
25:00 Setting up Apache Flink project
32:28 Consuming data from Kafka with Apache Flink
43:30 Starting Apache Flink on Mac
54:25 Writing Kafka Streams to Postgres Database
1:20:00 Aggregating Transactions per Category into Postgres
1:36:00 Aggregating Transactions Per Day into Postgres
1:39:46 Aggregating Transactions Per Month into Postgres
1:51:52 Writing Kafka Streams Data into Elasticsearch
2:05:00 Reindexing Data on Elasticsearch with Timestamp
2:10:52 Creating Streaming Dashboard on Elasticsearch
2:22:46 Realtime Dashboard Results
2:24:14 Recap
2:25:34 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Big Data Engineering, Apache Flink, Kafka, Elasticsearch, Docker, Data Engineering, Realtime Data Processing, Big Data, Data Pipeline, Streaming Data, Data Analytics, Tech Tutorial, Data Science, Flink Streaming, Kafka Streaming, Elasticsearch Tutorial, Docker Containers, Data Engineering Project, Realtime Analytics, Big Data Technologies, Data Engineering Tutorial, Data Engineering Projects, Data Engineer
✨Hashtags✨
#ApacheFlink, #Kafka, #Elasticsearch, #Docker, #DataEngineering, #RealtimeData, #BigData, #DataPipeline, #TechTutorial, #DataScience, #StreamingData, #Flink, #KafkaStreams, #ElasticsearchTips, #DockerContainers, #DataEngineeringProjects, #RealtimeAnalytics, #BigDataTech, #LearnDataEngineering, #dataengineers
Timestamp
0:00 Introduction
0:55 The system architecture
08:00 Sales Analytics Data Generation
19:10 Producing Data into Kafka Broker
25:00 Setting up Apache Flink project
32:28 Consuming data from Kafka with Apache Flink
43:30 Starting Apache Flink on Mac
54:25 Writing Kafka Streams to Postgres Database
1:20:00 Aggregating Transactions per Category into Postgres
1:36:00 Aggregating Transactions Per Day into Postgres
1:39:46 Aggregating Transactions Per Month into Postgres
1:51:52 Writing Kafka Streams Data into Elasticsearch
2:05:00 Reindexing Data on Elasticsearch with Timestamp
2:10:52 Creating Streaming Dashboard on Elasticsearch
2:22:46 Realtime Dashboard Results
2:24:14 Recap
2:25:34 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Big Data Engineering, Apache Flink, Kafka, Elasticsearch, Docker, Data Engineering, Realtime Data Processing, Big Data, Data Pipeline, Streaming Data, Data Analytics, Tech Tutorial, Data Science, Flink Streaming, Kafka Streaming, Elasticsearch Tutorial, Docker Containers, Data Engineering Project, Realtime Analytics, Big Data Technologies, Data Engineering Tutorial, Data Engineering Projects, Data Engineer
✨Hashtags✨
#ApacheFlink, #Kafka, #Elasticsearch, #Docker, #DataEngineering, #RealtimeData, #BigData, #DataPipeline, #TechTutorial, #DataScience, #StreamingData, #Flink, #KafkaStreams, #ElasticsearchTips, #DockerContainers, #DataEngineeringProjects, #RealtimeAnalytics, #BigDataTech, #LearnDataEngineering, #dataengineers
 2:26:01
2:26:01
Realtime Streaming with Apache Flink | End to End Data Engineering Project
 1:25:00
1:25:00
Building a Real-Time Data Streaming Pipeline using Apache Kafka, Flink and Postgres
 0:07:50
0:07:50
Intro to Stream Processing with Apache Flink | Apache Flink 101
 0:44:19
0:44:19
Build a Real-time Stream Processing Pipeline with Apache Flink on AWS - Steffen Hausmann
 0:09:43
0:09:43
What is Apache Flink®?
 0:16:04
0:16:04
Apache Flink Java Simple Project for Beginners(Real Time Payment UseCase)
 0:03:54
0:03:54
Apache Flink | A Real Time & Hands-On course on Flink - learn Apache Flink
 1:04:42
1:04:42
Apache Flink 101 | Building and Running Streaming Applications
 1:00:53
1:00:53
Building a Real-Time Data Streaming Pipeline using Kafka, Flink and Postgres | Stream 100K records
 0:00:55
0:00:55
Realtime Streaming with Apache Flink, Kafka, Elasticsearch and Postgres #dataengineering #realtime
 0:21:20
0:21:20
Real-time Stream Analytics and Scoring Using Apache Flink, Druid & Cassandra - Ciesielczyk &...
 0:31:24
0:31:24
AWS re:Invent 2020: Building real-time applications using Apache Flink
 0:55:56
0:55:56
Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools
 0:40:12
0:40:12
Real-Time Stream processing with Apache Flink
 0:31:20
0:31:20
Introduction to Stateful Stream Processing with Apache Flink • Robert Metzger • GOTO 2019
 0:41:18
0:41:18
Flexible and Real time Stream Processing with Apache Flink
 0:34:03
0:34:03
CDC Stream Processing with Apache Flink
 1:16:45
1:16:45
Java Training Real time processing Apache Flink
 0:15:45
0:15:45
How Nextdoor improves their customer experience in real time with Apache Flink
 0:12:06
0:12:06
Streaming Concepts & Introduction to Flink Series - What is Stream Processing & Apache Flink
 0:03:50
0:03:50
Using Kafka with Flink | Apache Flink 101
 0:26:30
0:26:30
Apache Flink for Real Time Data Analysis
 0:56:27
0:56:27
Introduction to Stream Processing with Apache Flink—Marta Paes Moreira
 0:28:38
0:28:38
Real-time analytics and anomaly detection with Apache Kafka, Apache Flink, Grafana & QuestDB
Комментарии