filmov
tv
Find consecutive duplicate words (using REGEX)

Показать описание
In this video I describe the process to write a shell script to highlight consecutive duplicate words in a file. To do so, we use regular expressions, grep and ripgrep.
Writing the same word twice without noticing is a common issue we encounter when we write long articles. Executing this script to highlight these words can save you a lot of time to make sure you don't submit a paper with these duplicate words.
Writing the same word twice without noticing is a common issue we encounter when we write long articles. Executing this script to highlight these words can save you a lot of time to make sure you don't submit a paper with these duplicate words.
 0:07:15
0:07:15
Find consecutive duplicate words (using REGEX)
 0:12:51
0:12:51
Codewars 7 kyu Remove Consecutive Duplicate Words Javascript
 0:09:05
0:09:05
Consecutive Characters | LeetCode 1446 | C++, Java, Python
 0:10:29
0:10:29
Consecutive Characters 🔥| Leetcode 1446 | Strings
 0:08:27
0:08:27
Remove adjacent duplicates in a string
 0:06:26
0:06:26
Remove Duplicates - String | Javascript Tutorial | LetCode
 0:17:18
0:17:18
Remove Consecutive Repeated Letters in a String Java Program | ICSE Class 10 Computer
 0:05:44
0:05:44
Remove duplicates from a string
 0:13:50
0:13:50
Q60- Remove Consecutive Duplicates in Java | Remove Consecutive Duplicates From String #java
 0:13:45
0:13:45
Remove Duplicate Character From String || Remove Repeated Character || Java Program
 0:05:58
0:05:58
Javascript Challenges - Count Repeating Letters
 0:07:19
0:07:19
How to find duplicate characters in a string in Java | Automation testing interview question
 0:06:45
0:06:45
QA Interview Programs|| Strings||Remove Consecutive Duplicates
 0:01:54
0:01:54
Removing consecutive duplicates using Stack| JAVA
 0:32:25
0:32:25
Coding Ninja String in Java | Check Permutation | Remove Consecutive Duplicates | Reverse Each Word
 0:09:43
0:09:43
Remove All Adjacent Duplicates In String | Removing consecutive duplicates | Stack Playlist Hindi
 0:08:00
0:08:00
Write Java program to count Character Occurrences in given string
 0:06:24
0:06:24
Write an interactive C program to remove the duplicates in a given word (string) (HIndi)
 0:08:06
0:08:06
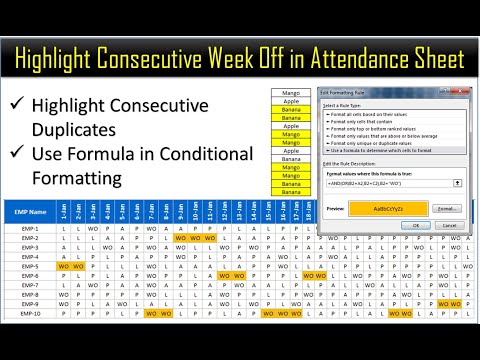
Highlight Consecutive Weekly off in Attendance Sheet Using Conditional Formatting
 0:10:51
0:10:51
Remove Consecutive Duplicates #java
 0:08:47
0:08:47
C# Program to remove duplicate characters from a string
 0:05:43
0:05:43
Java Program to Remove Duplicate Elements from Sorted Array
 0:03:59
0:03:59
Python program to print duplicate values in a list tutorial | Duplicate elements
 0:02:51
0:02:51
Remove Duplicate/Repeated words from String | GeeksforGeeks
Комментарии