filmov
tv
Python Scrapy Tutorial - 20 - Scraping Websites with Pagination

Показать описание
In this web scraping video we learn how to scrape multiple pages using URL's / websites with Pagination.
Next video - Logging in with Scrapy FormRequest
#python
Next video - Logging in with Scrapy FormRequest
#python

Python Scrapy Tutorial - 20 - Scraping Websites with Pagination

Scrapy Course – Python Web Scraping for Beginners

Scrapy for Beginners - A Complete How To Example Web Scraping Project

Web Scraping with Scrapy: Python Tutorial

Python Scrapy Tutorial - 21 - Logging in with Scrapy FormRequest

Python Scrapy Tutorial | Web Scraping and Crawling Using Scrapy | Edureka

Python Scrapy for Beginners — A Complete Web Scraping Project [Web Scraping with Python]

Python Scrapy Tutorial - Cats & Spiders? Web Scraping Reddit with Scrapy [2020]

Python Scrapy Tutorial - 3 - Robots.txt and Web Scraping Rules

Learn Scrapy in just 20 Minutes

Coding Web Crawler in Python with Scrapy

Extract all the data! - 02 - Python scrapy tutorial for beginners

Scraping Indeed.com With Python Scrapy (2022)

Scrapy Tutorial: How to Crawl & Scrape any website using Scrapy and Python

Python Scrapy Tutorial- 1 - Web Scraping, Spiders and Crawling

Scrapy Tutorial: Python Web Scraping

Python Web Scraping Tutorial 20 – API and Web Scraping Together

Python Scrapy Tutorial - 12 - Item containers ( Storing scraped data )

How to use Scrapy Items - 05 - Python Scrapy tutorial for beginners

Python Scrapy Tutorial - 18 - Storing data in MongoDB
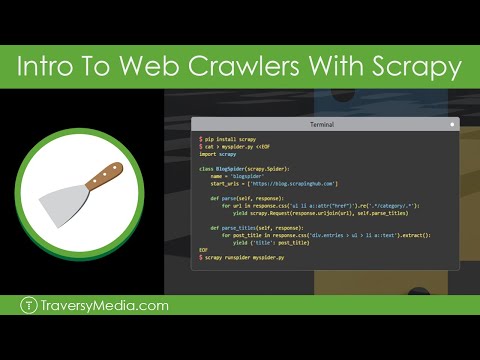
Intro To Web Crawlers & Scraping With Scrapy

Python Scrapy Tutorial- 6 - Project Structure in Scrapy

Python Scrapy Tutorial - 19 - Web Crawling & Following links

Ultimate WEB SCRAPING guide on Code Monkey King's YouTube channel
Комментарии