filmov
tv
Comfy UI K sampler Explained | How AI Image generation works | Simple explanation
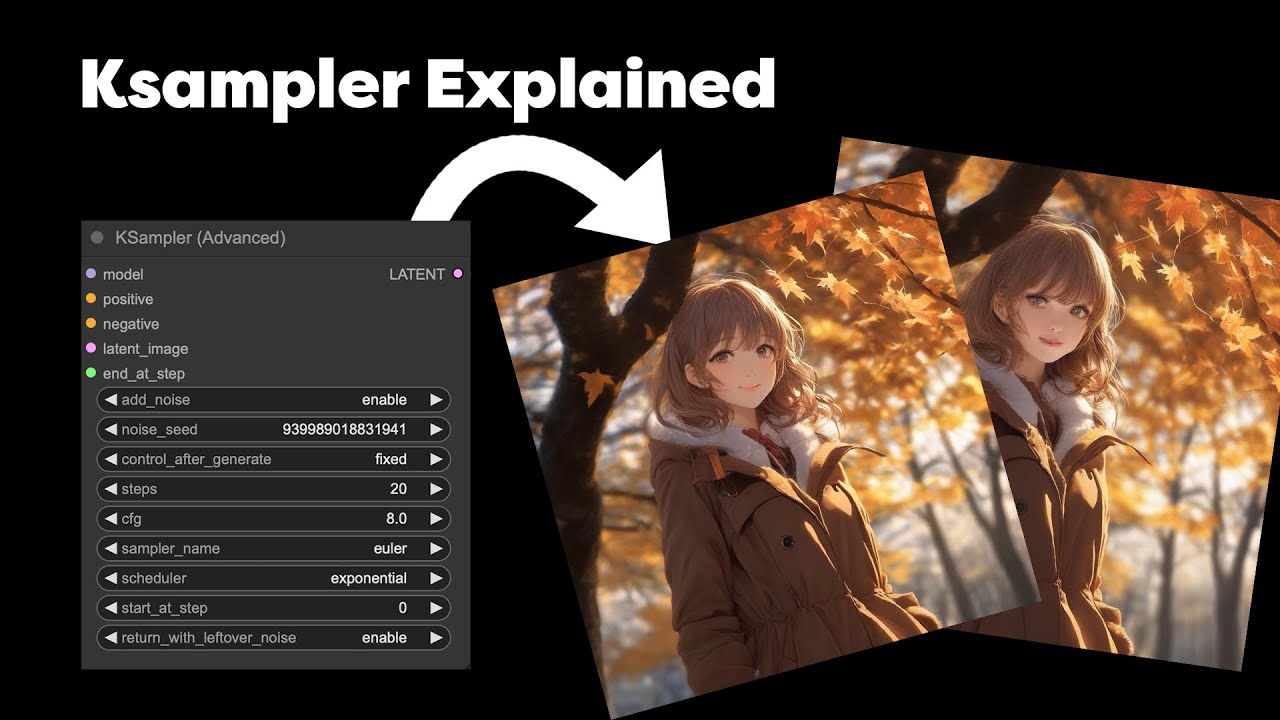
Показать описание
This is my attempt to try and explain how Ksamplers in comfy UI work, while also explaining a VERY simplified explanation of how Stable diffusion and Image generation works.
If you want to support the channel please do so at
If you want to support the channel please do so at
 0:08:54
0:08:54
Comfy UI K sampler Explained | How AI Image generation works | Simple explanation
 0:15:14
0:15:14
L1: Using ComfyUI, EASY basics - Comfy Academy
 0:20:08
0:20:08
ComfyUI EP02: AI Image Generation Process (Details of K-Sampler Node) [Stable Diffusion]
 0:12:49
0:12:49
Stable Diffusion 09 How to Choose a Sampler
 0:13:54
0:13:54
A look at the NEW ComfyUI Samplers & Schedulers!
 0:20:18
0:20:18
ComfyUI: Advanced Understanding (Part 1)
 0:19:01
0:19:01
ComfyUI - Getting Started : Episode 1 - Better than AUTO1111 for Stable Diffusion AI Art generation
 0:17:07
0:17:07
Stable Diffusion Samplers - Which samplers are the best and all settings explained!
 0:17:34
0:17:34
ComfyUI SDXL Advanced Setup Part 5 - Adv dual sampler
 0:20:26
0:20:26
Complete Comfy UI Guide Part 1 | Beginner to Pro Series
 0:23:28
0:23:28
ComfyUI Tutorial Series: Ep02 - Nodes and Workflow Basics
 0:09:28
0:09:28
ComfyUI - Getting Started : Episode 2 - Custom Nodes Everyone Should Have
 0:21:32
0:21:32
LATENT Tricks - Amazing ways to use ComfyUI
 0:03:39
0:03:39
ComfyUI Impact Pack - Tutorial #7: Advanced IMG2IMG using Regional Sampler
 0:27:29
0:27:29
Understanding ComfyUI Nodes: A Comprehensive Guide
 0:06:34
0:06:34
ComfyUI Impact Pack: Tutorial #5 - Preventing Prompt Bleeding based on Regional Samplers
 0:33:42
0:33:42
ComfyUI: Area Composition, Multi Prompt Workflow Tutorial
 0:12:45
0:12:45
How to install and use ComfyUI - Stable Diffusion.
 0:17:56
0:17:56
ComfyUI for Beginner - Part - 1 - Stable Diffusion
 0:10:06
0:10:06
ComfyUI Impact Pack: Tutorial #6 - Regional LoRA based on Regional Samplers
 0:19:27
0:19:27
Why ComfyUI is The BEST UI for Stable Diffusion!
 0:42:31
0:42:31
ComfyUI - Prompt Engineering with CFG, Sampler Steps and Clip Skipping - for Stable Diffusion Users
 0:10:10
0:10:10
1000% FASTER Stable Diffusion in ONE STEP!
 0:17:26
0:17:26
ComfyUI Tutorial Series: Ep04 - IMG2IMG and LoRA Basics
Комментарии