filmov
tv
Web Crawler - CS101 - Udacity

Показать описание
Sergey Brin, co-founder of Google, introduces the class. What is a web-crawler and why do you need one?
All units in this course below:
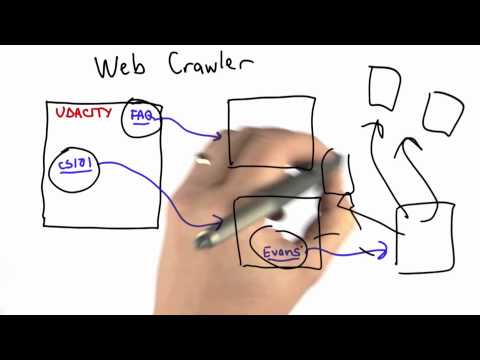 0:04:03
0:04:03
Web Crawler - CS101 - Udacity
 0:04:03
0:04:03
02 - Web Crawler - CS101 - Udacity
 0:02:06
0:02:06
Finishing the Web Crawler - Intro to Computer Science
 0:00:40
0:00:40
Finishing the Web Crawler Solution - Intro to Computer Science
 0:01:04
0:01:04
Crawl Web - Intro to Computer Science
 0:03:14
0:03:14
Web Scraping vs Web Crawling Explained
 0:04:16
0:04:16
Finishing the Web Crawler - Intro to Computer Science
 0:01:19
0:01:19
Crawling Process - Intro to Computer Science
 0:00:51
0:00:51
Finishing Crawl Web - Intro to Computer Science
 0:00:59
0:00:59
Crawl Web Loop - Intro to Computer Science
 0:03:12
0:03:12
What is Web Crawler and How Does It Work?
 0:00:11
0:00:11
Crawl Web Solution - Intro to Computer Science
 0:00:30
0:00:30
Pickle the Crawl - Intro to Computer Science
 0:01:37
0:01:37
Crawl Web Loop Solution - Intro to Computer Science
 0:06:11
0:06:11
Web Crawling vs. Web Scraping: The battle for data extraction dominance!
 0:01:40
0:01:40
What Is Web Crawler? Web Crawler Explained In 90 Seconds (2024)
 0:02:56
0:02:56
Web Crawling vs. Web Scraping - What is the Difference?
 0:04:18
0:04:18
Introduction to web browsers - CS101 Unit 2 - Udacity
 0:02:34
0:02:34
Web-crawler basic example
 0:03:43
0:03:43
Web Scraping vs. Web Crawling - what's the difference?
 0:09:12
0:09:12
Web Scraping vs Web Crawling - What is the Difference?
 0:00:36
0:00:36
Crawl If - Intro to Computer Science
 0:01:03
0:01:03
Finishing Crawl Web Solution - Intro to Computer Science
 0:01:30
0:01:30
Webcrawler - Bedeutung von Crawler, Spider oder Bots in der SEO
Комментарии