filmov
tv
Dynamic Databricks Workflows - Advancing Spark

Показать описание
Last week saw the General Availability of dynamic functionality for Databricks Workflows, in the form of the parameterized ForEach activity, but what does that mean? And why should we care?
For a long time we've been using external orchestration tools whenever things had to be flexible, metadata driven or simply at a large scale - but with these changes we have a cheap, flexible way of achieving some pretty complex orchestration inside of Databricks itself!
In this video Simon looks at a quick pattern for running a medallion-style lake processing routine, all driven by some JSON metadata!
For a long time we've been using external orchestration tools whenever things had to be flexible, metadata driven or simply at a large scale - but with these changes we have a cheap, flexible way of achieving some pretty complex orchestration inside of Databricks itself!
In this video Simon looks at a quick pattern for running a medallion-style lake processing routine, all driven by some JSON metadata!
 0:21:56
0:21:56
Dynamic Databricks Workflows - Advancing Spark
 0:08:10
0:08:10
Databricks Workflows
 0:37:58
0:37:58
How to Create Databricks Workflows (new features explained)
 0:14:07
0:14:07
Advancing Spark - Learning Databricks with DBDemos
 0:43:42
0:43:42
Databricks Workflows: Practical How-Tos and Demos
 0:33:17
0:33:17
Turbocharge your AI/ML Databricks workflows with Precisely
 0:18:27
0:18:27
Advancing Spark - Multi-Task Databricks Jobs
 0:17:17
0:17:17
83. Databricks | Pyspark | Databricks Workflows: Job Scheduling
 0:42:17
0:42:17
Databricks Mastery Hands On Big Data, ETL, and Lakehouse Transformation - Part 1
 0:05:57
0:05:57
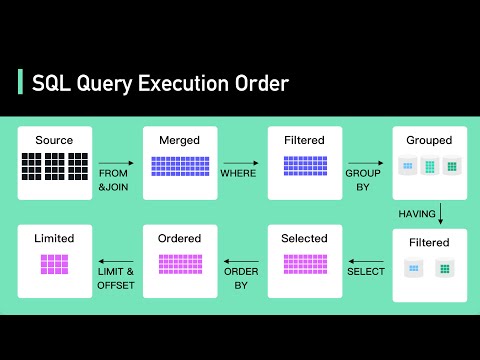
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 1:27:52
1:27:52
Delta Live Tables A to Z: Best Practices for Modern Data Pipelines
 0:08:28
0:08:28
100+ Docker Concepts you Need to Know
 0:54:49
0:54:49
Ask Databricks about Databricks Workflows with Simon Whiteley and Roland Fäustlin.
 0:22:02
0:22:02
Advancing Spark - Databricks Runtime 9
 0:33:20
0:33:20
Advancing Spark - Databricks Delta Live Tables First Look
 0:15:37
0:15:37
Advancing Spark - Introduction to Databricks Marketplace
 0:20:33
0:20:33
Advancing Spark - Databricks Delta Live Tables with SQL Syntax
 0:23:00
0:23:00
Advancing Spark - Understanding Terraform
 0:55:03
0:55:03
Data Collab Lab: Automate Data Pipelines with PySpark SQL
 0:54:45
0:54:45
Ask Databricks about monitoring Databricks Workflows with Simon Whiteley and Stacy Kerkela.
 0:48:37
0:48:37
Building Advance Analytics pipelines with Azure Databricks - Lace Lofranco
 0:25:15
0:25:15
22 Workflows, Jobs & Tasks | Pass Values within Tasks | If Else Cond | For Each Loop & Re-Ru...
 0:25:53
0:25:53
Advancing Spark - Azure Databricks News August 2022
 0:24:33
0:24:33
Migrating Apache Hive Workload to Apache Spark (Zhan Zhang & Jane Wang)
Комментарии