filmov
tv
Percent Change and Correlation Tables - p.8 Data Analysis with Python and Pandas Tutorial

Показать описание
Welcome to Part 8 of our Data Analysis with Python and Pandas tutorial series. In this part, we're going to do some of our first manipulations on the data.
 0:20:20
0:20:20
Percent Change and Correlation Tables - p.8 Data Analysis with Python and Pandas Tutorial
 0:07:34
0:07:34
Python Tutorial: Learn Statistical in Pandas-Percentage Change, Covariance, Correlation in 7 Minutes
 0:25:52
0:25:52
#51 Pandas (Part 28) Percent change, Covariance, Correlation in Python | Tutorial
 0:01:12
0:01:12
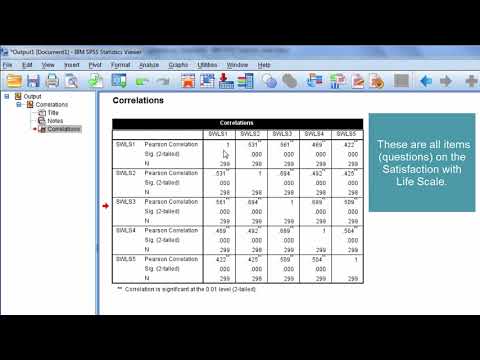
How to Interpret a Correlation Matrix
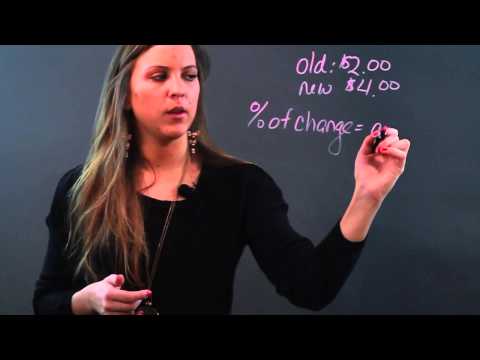 0:01:47
0:01:47
How to Figure Out the Percentage of Increase Between Two Differences
 0:07:41
0:07:41
How to add asterisks to a correlation table to show the significance in excel
 0:02:19
0:02:19
How to make a report-ready correlation matrix quickly using SPSS and Excel
 0:09:54
0:09:54
Python: Percent change calculation how to tutorial
 0:12:24
0:12:24
Percent Change Method Explanation in Pandas for Python: .pct_change() and All Parameters
 0:05:49
0:05:49
Calculating Percentage Change in Right way, Mean, Median, Mode in Excel By T&T
 0:04:15
0:04:15
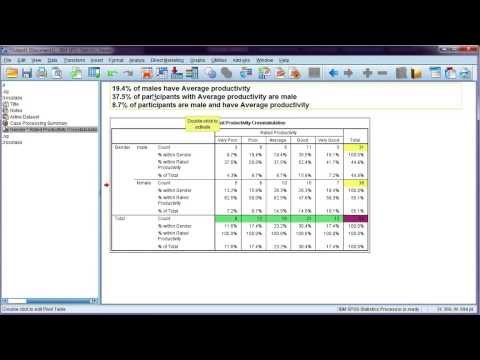
Interpreting percentages from a cross tabulation table in SPSS
 0:02:21
0:02:21
AEM 3100 Percent Change Forecasting
 0:05:22
0:05:22
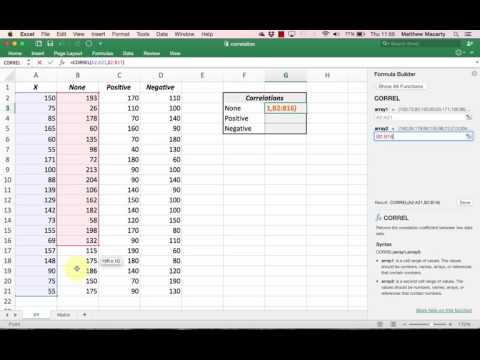
Using Excel to calculate a correlation coefficient || interpret relationship between variables
 0:01:21
0:01:21
How to calculate the frequencies and precentages in SPSS
 0:09:43
0:09:43
Correlation Matrix (Numerical) | Feature Selection | Python
 0:04:38
0:04:38
What is a Correlation Matrix - Business Statistics Tips
 0:11:26
0:11:26
Perform Basic Correlation Analysis in Excel
 0:03:37
0:03:37
Draw Correlation Plot in Origin Pro | Correlation Coefficient | Very Easy
 0:09:26
0:09:26
How To... Calculate Pearson's Correlation Coefficient (r) by Hand
 0:03:23
0:03:23
How to Calculate Percent Change (Growth Rate) in Pandas (Pct_Change) in Python
 0:13:35
0:13:35
#48. Descriptive Statistics - 7: Rank, percent, cumulative sum, product, min, max | Tutorial
 0:01:24
0:01:24
Calculate Rate of Change in Microsoft Excel (Shortcut) | Excel Nerds
 0:04:15
0:04:15
Finding Percent Change in Data on a Line Graph
 0:40:01
0:40:01
Significance Testing Contingency Tables and Correlations
Комментарии