filmov
tv
Improving throughput and latency with Flink's network stack - Nico Kruber

Показать описание
Flink Forward Berlin, September 2018 #flinkforward
Flink's network stack is designed with two goals in mind: (a) having low latency for data passing through, and (b) achieving an optimal throughput. It already achieves a good trade-off between these two but we will continue to tune it further for an optimal one. Flink 1.5 did not only further reduce overhead inside the network stack, but also introduced some groundbreaking changes in the stack itself, introducing an own (credit-based) flow control mechanism and a general change towards a more network-event-driven pull approach. With our own flow control, we steer what data is sent on the wire and make sure that the receiver has capacity to handle it. If there is no capacity, we will backpressure earlier and allow checkpoint barriers to pass through more quickly which improves checkpoint alignment and overall checkpoint speed.
In this talk, we will describe in detail how the network stack works with respect to (de)serialization, memory management and buffer pools, the different actor threads involved, configuration, as well as the design to improve throughput and latency trade-offs in the network and processing pipelines. We will go into detail on what is happening during checkpoint alignments and how credit-based flow control improves them. Additionally, we will present common pitfalls as well as debugging techniques to find network-related issues in your Flink jobs.
Flink's network stack is designed with two goals in mind: (a) having low latency for data passing through, and (b) achieving an optimal throughput. It already achieves a good trade-off between these two but we will continue to tune it further for an optimal one. Flink 1.5 did not only further reduce overhead inside the network stack, but also introduced some groundbreaking changes in the stack itself, introducing an own (credit-based) flow control mechanism and a general change towards a more network-event-driven pull approach. With our own flow control, we steer what data is sent on the wire and make sure that the receiver has capacity to handle it. If there is no capacity, we will backpressure earlier and allow checkpoint barriers to pass through more quickly which improves checkpoint alignment and overall checkpoint speed.
In this talk, we will describe in detail how the network stack works with respect to (de)serialization, memory management and buffer pools, the different actor threads involved, configuration, as well as the design to improve throughput and latency trade-offs in the network and processing pipelines. We will go into detail on what is happening during checkpoint alignments and how credit-based flow control improves them. Additionally, we will present common pitfalls as well as debugging techniques to find network-related issues in your Flink jobs.
 0:40:12
0:40:12
 0:00:55
0:00:55
 0:09:25
0:09:25
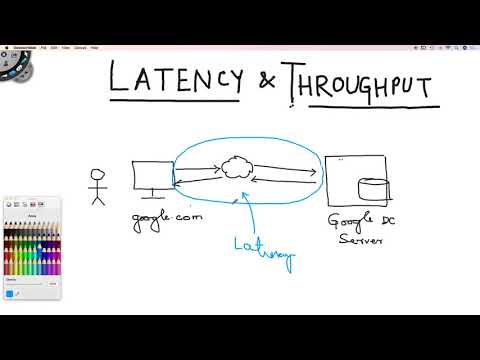 0:02:28
0:02:28
 0:20:51
0:20:51
 0:01:38
0:01:38
 0:06:01
0:06:01
 0:35:12
0:35:12
 0:14:58
0:14:58
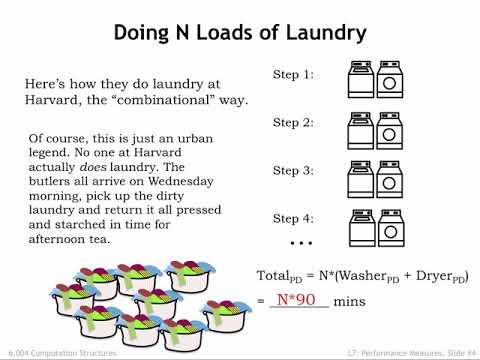 0:06:17
0:06:17
 0:03:30
0:03:30
 0:17:44
0:17:44
 0:04:56
0:04:56
 0:02:42
0:02:42
 0:05:04
0:05:04
 0:05:06
0:05:06
 0:19:36
0:19:36
 0:00:13
0:00:13
 0:13:07
0:13:07
 0:48:58
0:48:58
 0:08:59
0:08:59
 0:06:16
0:06:16
 0:06:41
0:06:41
 0:00:50
0:00:50