filmov
tv
How to properly encode a long text to utf 8 properly in python
Показать описание
Title: Properly Encoding Long Text to UTF-8 in Python: A Step-by-Step Tutorial
Introduction:
UTF-8 is a widely used character encoding that supports the representation of almost all characters in the Unicode character set. When dealing with long texts in Python, it's crucial to ensure proper encoding to avoid potential issues with character representation. In this tutorial, we'll guide you through the process of encoding long text to UTF-8 in Python, with detailed explanations and code examples.
Step 1: Understanding Character Encoding and UTF-8:
Character encoding is a method of representing characters in a way that can be understood by computers. UTF-8 is a variable-width character encoding that can represent every character in the Unicode character set. Each character is represented by a variable number of bytes, depending on its Unicode code point.
Step 2: Reading the Text File:
Replace 'your_file_encoding' with the actual encoding of your text file. Common encodings include 'utf-8', 'latin-1', 'utf-16', etc.
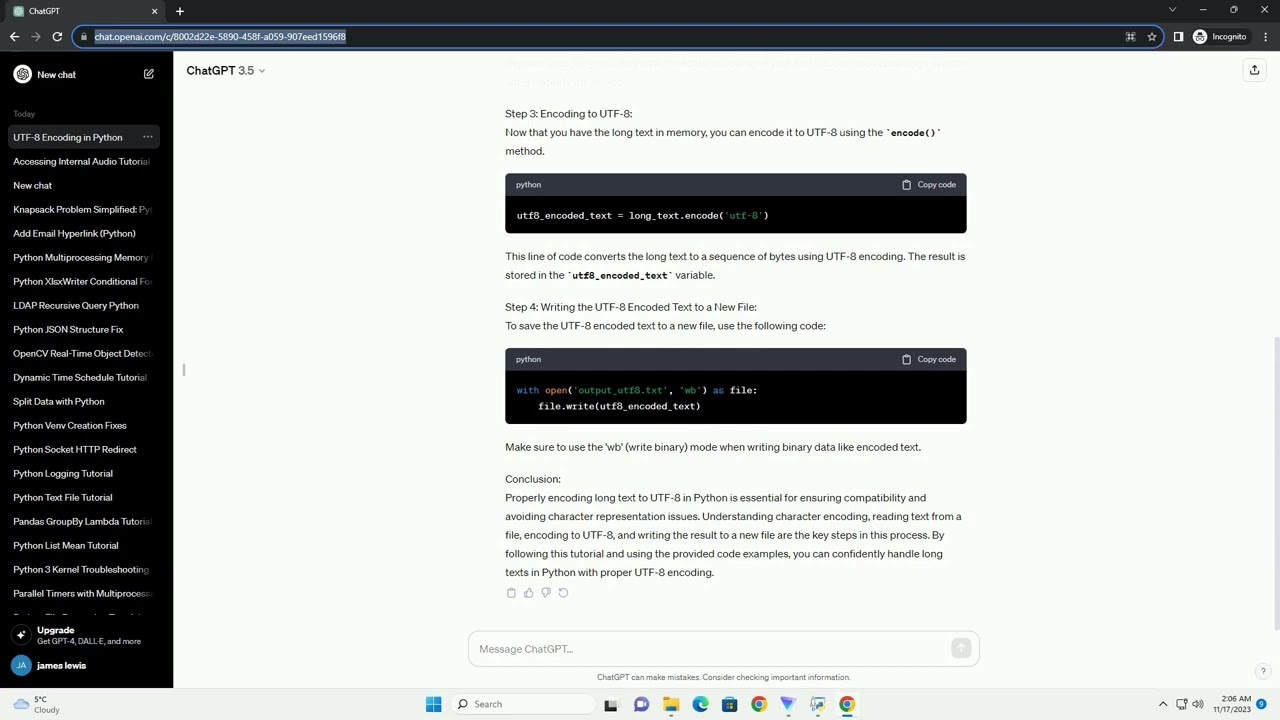
Step 3: Encoding to UTF-8:
Now that you have the long text in memory, you can encode it to UTF-8 using the encode() method.
This line of code converts the long text to a sequence of bytes using UTF-8 encoding. The result is stored in the utf8_encoded_text variable.
Step 4: Writing the UTF-8 Encoded Text to a New File:
To save the UTF-8 encoded text to a new file, use the following code:
Make sure to use the 'wb' (write binary) mode when writing binary data like encoded text.
Conclusion:
Properly encoding long text to UTF-8 in Python is essential for ensuring compatibility and avoiding character representation issues. Understanding character encoding, reading text from a file, encoding to UTF-8, and writing the result to a new file are the key steps in this process. By following this tutorial and using the provided code examples, you can confidently handle long texts in Python with proper UTF-8 encoding.
ChatGPT
Introduction:
UTF-8 is a widely used character encoding that supports the representation of almost all characters in the Unicode character set. When dealing with long texts in Python, it's crucial to ensure proper encoding to avoid potential issues with character representation. In this tutorial, we'll guide you through the process of encoding long text to UTF-8 in Python, with detailed explanations and code examples.
Step 1: Understanding Character Encoding and UTF-8:
Character encoding is a method of representing characters in a way that can be understood by computers. UTF-8 is a variable-width character encoding that can represent every character in the Unicode character set. Each character is represented by a variable number of bytes, depending on its Unicode code point.
Step 2: Reading the Text File:
Replace 'your_file_encoding' with the actual encoding of your text file. Common encodings include 'utf-8', 'latin-1', 'utf-16', etc.
Step 3: Encoding to UTF-8:
Now that you have the long text in memory, you can encode it to UTF-8 using the encode() method.
This line of code converts the long text to a sequence of bytes using UTF-8 encoding. The result is stored in the utf8_encoded_text variable.
Step 4: Writing the UTF-8 Encoded Text to a New File:
To save the UTF-8 encoded text to a new file, use the following code:
Make sure to use the 'wb' (write binary) mode when writing binary data like encoded text.
Conclusion:
Properly encoding long text to UTF-8 in Python is essential for ensuring compatibility and avoiding character representation issues. Understanding character encoding, reading text from a file, encoding to UTF-8, and writing the result to a new file are the key steps in this process. By following this tutorial and using the provided code examples, you can confidently handle long texts in Python with proper UTF-8 encoding.
ChatGPT
 0:08:39
0:08:39
 0:03:38
0:03:38
 0:04:05
0:04:05
 0:01:38
0:01:38
 0:20:52
0:20:52
 0:03:42
0:03:42
 0:01:21
0:01:21
 0:15:31
0:15:31
 0:46:10
0:46:10
 0:26:00
0:26:00
 0:06:10
0:06:10
 0:17:55
0:17:55
 0:03:11
0:03:11
 0:03:36
0:03:36
 0:19:44
0:19:44
 0:01:30
0:01:30
 0:01:30
0:01:30
 0:22:18
0:22:18
 0:01:39
0:01:39
 0:27:59
0:27:59
 0:08:32
0:08:32
 0:13:54
0:13:54
 0:00:59
0:00:59
 0:01:46
0:01:46