filmov
tv
Vertex AI Matching Engine - Vector Similarity Search

Показать описание
Putting a similarity index into production at scale is a pretty hard challenge. It requires a whole bunch of infrastructure working closely together. You need to handle a large amount of data at low latency. It introduces you to topics like sharding, hashing, trees, load balancing, efficient data transfer, data replication, and much more.
Check out the notebook and the article on how to get started with Google Cloud Vertex AI Matching Engine
If you enjoyed this video, please subscribe to the channel ❤️
🎉 Subscribe for Article and Video Updates!
You can find me here:
If you or your company is looking for advice on the cloud or ML, check out the company I work for.
We offer consulting, workshops, and training at zero cost. Imagine an extension for your team without additional costs.
#vertexai #googlecloud #machinelearning #mlengineer #doit
▬ My current recording equipment ▬▬▬▬▬▬▬▬
Support my channel if you buy with those links on Amazon
▬ Timestamps ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
00:00 Introduction
00:32 Statement
00:47 Use Cases
01:25 Embedding
01:47 Input
02:23 Types
02:54 VPC
04:05 Create Embeddings
06:50 Setup
07:00 VPC Setup
08:39 Create Index
11:58 Create Endpoint
13:00 Deploy Index
14:23 Update Index
15:10 Scale Index
16:46 Query
22:23 Bye
Check out the notebook and the article on how to get started with Google Cloud Vertex AI Matching Engine
If you enjoyed this video, please subscribe to the channel ❤️
🎉 Subscribe for Article and Video Updates!
You can find me here:
If you or your company is looking for advice on the cloud or ML, check out the company I work for.
We offer consulting, workshops, and training at zero cost. Imagine an extension for your team without additional costs.
#vertexai #googlecloud #machinelearning #mlengineer #doit
▬ My current recording equipment ▬▬▬▬▬▬▬▬
Support my channel if you buy with those links on Amazon
▬ Timestamps ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
00:00 Introduction
00:32 Statement
00:47 Use Cases
01:25 Embedding
01:47 Input
02:23 Types
02:54 VPC
04:05 Create Embeddings
06:50 Setup
07:00 VPC Setup
08:39 Create Index
11:58 Create Endpoint
13:00 Deploy Index
14:23 Update Index
15:10 Scale Index
16:46 Query
22:23 Bye
 0:11:30
0:11:30
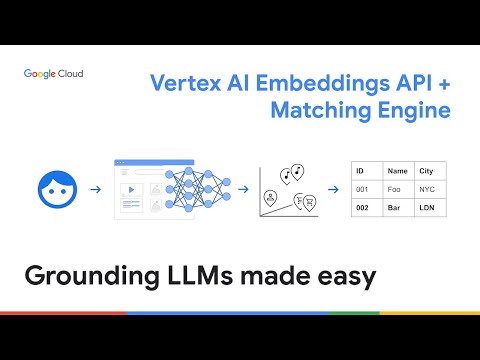
Vertex AI Embeddings API + Matching Engine: Grounding LLMs made easy
 0:22:42
0:22:42
Vertex AI Matching Engine - Vector Similarity Search
 0:09:22
0:09:22
Get Started with Vector Search using Vertex AI
 0:13:43
0:13:43
Building a question answering system with Vertex AI
 0:07:16
0:07:16
What is Vertex AI?
 0:35:31
0:35:31
Grounding for Gemini with Vertex AI Search and DIY RAG
 0:20:12
0:20:12
Building a Machine Learning Model with Google Vertex AI: A Step-by-Step Guide
 0:05:59
0:05:59
Introduction to Vertex AI Model Garden
 0:17:19
0:17:19
Get started with Vertex AI
 0:08:16
0:08:16
How to Use Vertex AI API in Google Cloud
 0:05:16
0:05:16
Grounding in Vertex AI
 0:17:35
0:17:35
Serving Machine Learning models with Google Vertex AI
 0:07:42
0:07:42
Which AI/ML solution on Vertex AI is right for me?
 0:01:20
0:01:20
How to classify images with Vertex AI
 0:06:02
0:06:02
Analyzing unstructured data in BigQuery with Vertex AI
 0:02:54
0:02:54
Bringing BigQuery data into Vertex AI Workbench
 0:09:01
0:09:01
Building an Enterprise Search app using Vertex AI Search on Google Cloud (Demo)
 0:22:15
0:22:15
Vertex AI | PALM API | Langchain matching engine | Personal Document Chat BOT | Generative AI |BARD
 0:38:42
0:38:42
Accelerate your generative AI projects with new tools on Vertex AI
 0:00:55
0:00:55
What is Vertex AI?
 0:58:52
0:58:52
Google Cloud Vertex AI Platform | DataHour by Mona Mona
 0:06:52
0:06:52
No-Code AI Search (with Your Data) on Vertex AI (GCP)
 0:06:01
0:06:01
Introduction to Colab Enterprise on Vertex AI
 0:05:36
0:05:36
Build AI-powered apps on Vertex AI with LangChain
Комментарии