filmov
tv
GPTs in Probabilistic Programming with Daniel Lee

Показать описание
This will be a high-level talk discussing the separation of statistical models and inference algorithms.
Things we’d like to talk about:
- The general vernacular combines two concepts together: model + inference. But they can be thought of separately.
- Given a statistical model, there are (at least) 3 different types of inference. Optimization, approximate inference, Bayesian inference. We’ll talk about some of the use cases of each. And where stochastic optimization fits in.
- A description of GPTs and how it can be implemented in Stan (and similarly in PyMC or any other PPL).
This talk won’t be overly technical. The goal will be to try to solidify the differences between the different types of inference and when to apply them.
#GPTs #ProbabilisticProgramming #MachineLearning #NLP #AI #BayesianInference #Programming #NeuralNetworks #DataScience #ProbabilisticModels
Resources
## About the speakers
Daniel Lee
Daniel Lee is at Zelus Analytics working on player projection models across multiple sports. Daniel is a computational Bayesian statistician who helped create and develop Stan, the open-source statistical modeling language with over 20 years of experience in numeric computation and software; over 10 years of experience creating and working with Stan; and 5 years working on pharma-related models including joint models for estimating oncology treatment efficacy and PK/PD models. Past projects have covered estimating vote share for state and national elections; clinical trials for rare diseases and non-small-cell lung cancer; satellite control software for television and government; retail price sensitivity; data fusion for U.S. Navy applications; sabermetrics for an MLB team; and assessing “clutch” moments in NFL footage. He holds a B.S. in Mathematics with Computer Science from MIT, and a Master of Advanced Studies in Statistics from Cambridge University.
Dr. Thomas Wiecki (PyMC Labs)
Dr. Thomas Wiecki is an author of PyMC, the leading platform for statistical data science. To help businesses solve some of their trickiest data science problems, he assembled a world-class team of Bayesian modelers and founded PyMC Labs -- the Bayesian consultancy. He did his PhD at Brown University studying cognitive neuroscience.
## Connecting with PyMC Labs
## Timestamps
00:00 Webinar begins
00:59 About speaker
08:25 The problem
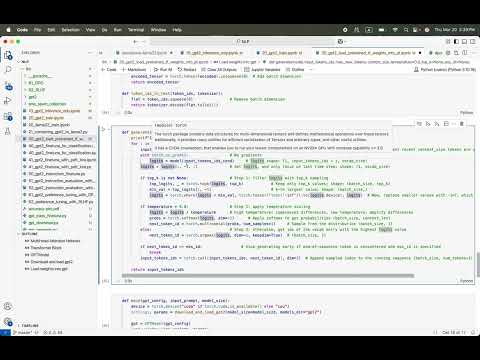
09:10 Generative Pre-trained transformer
10:13 Building a GPT in Stan
10:56 Data
14:13 Bigram model
15:39 Embedding size
17:26 Q/A We are not placing any priors ...?
18:41 Positional embedding
20:02 Self-Attention
20:50 Self-Attention example
22:02 Self-Attention function
24:47 Multi-Headed Self-Attention
25:17 Multi-Headed Self-Attention (example)
26:35 Multi-Headed Self-Attention (function)
27:24 Feed Forward, Skip connection, Larger Feed Forward ...
28:18 There's a statistical model
29:52 Inference is separate
30:05 Three types of inference
33:24 Inference on GPT
34:33 When to use/not use
37:14 Takeaways
37:27 Recap
37:37 References
38:38 Q/A What the query would map to ...?
40:18 Q/A How do you know the approximate inference algorithm ...?
42:05 Q/A Could you speak more on batching of data ...?
44:07 Q/A Do you think there is anything applicable by separating ...?
58:07 Q/A Another potential issue is ...
59:59 Webinar ends
#bayes #statistics #probabilistic
Things we’d like to talk about:
- The general vernacular combines two concepts together: model + inference. But they can be thought of separately.
- Given a statistical model, there are (at least) 3 different types of inference. Optimization, approximate inference, Bayesian inference. We’ll talk about some of the use cases of each. And where stochastic optimization fits in.
- A description of GPTs and how it can be implemented in Stan (and similarly in PyMC or any other PPL).
This talk won’t be overly technical. The goal will be to try to solidify the differences between the different types of inference and when to apply them.
#GPTs #ProbabilisticProgramming #MachineLearning #NLP #AI #BayesianInference #Programming #NeuralNetworks #DataScience #ProbabilisticModels
Resources
## About the speakers
Daniel Lee
Daniel Lee is at Zelus Analytics working on player projection models across multiple sports. Daniel is a computational Bayesian statistician who helped create and develop Stan, the open-source statistical modeling language with over 20 years of experience in numeric computation and software; over 10 years of experience creating and working with Stan; and 5 years working on pharma-related models including joint models for estimating oncology treatment efficacy and PK/PD models. Past projects have covered estimating vote share for state and national elections; clinical trials for rare diseases and non-small-cell lung cancer; satellite control software for television and government; retail price sensitivity; data fusion for U.S. Navy applications; sabermetrics for an MLB team; and assessing “clutch” moments in NFL footage. He holds a B.S. in Mathematics with Computer Science from MIT, and a Master of Advanced Studies in Statistics from Cambridge University.
Dr. Thomas Wiecki (PyMC Labs)
Dr. Thomas Wiecki is an author of PyMC, the leading platform for statistical data science. To help businesses solve some of their trickiest data science problems, he assembled a world-class team of Bayesian modelers and founded PyMC Labs -- the Bayesian consultancy. He did his PhD at Brown University studying cognitive neuroscience.
## Connecting with PyMC Labs
## Timestamps
00:00 Webinar begins
00:59 About speaker
08:25 The problem
09:10 Generative Pre-trained transformer
10:13 Building a GPT in Stan
10:56 Data
14:13 Bigram model
15:39 Embedding size
17:26 Q/A We are not placing any priors ...?
18:41 Positional embedding
20:02 Self-Attention
20:50 Self-Attention example
22:02 Self-Attention function
24:47 Multi-Headed Self-Attention
25:17 Multi-Headed Self-Attention (example)
26:35 Multi-Headed Self-Attention (function)
27:24 Feed Forward, Skip connection, Larger Feed Forward ...
28:18 There's a statistical model
29:52 Inference is separate
30:05 Three types of inference
33:24 Inference on GPT
34:33 When to use/not use
37:14 Takeaways
37:27 Recap
37:37 References
38:38 Q/A What the query would map to ...?
40:18 Q/A How do you know the approximate inference algorithm ...?
42:05 Q/A Could you speak more on batching of data ...?
44:07 Q/A Do you think there is anything applicable by separating ...?
58:07 Q/A Another potential issue is ...
59:59 Webinar ends
#bayes #statistics #probabilistic
 1:00:03
1:00:03
GPTs in Probabilistic Programming with Daniel Lee
 0:02:23
0:02:23
ChatGPT: Where Predictions Meet Probability
 0:35:46
0:35:46
How to Design the Perfect Custom GPT
 0:07:32
0:07:32
Probabilistic Programming for Investors
 0:54:05
0:54:05
Automatic Integration and Differentiation of Probabilistic Programs
 0:04:31
0:04:31
GPT Builder 🚀 Create Your Own GPTs and Infuse Knowledge. (FULL Tutorial) Step-by-Step 🤯
 0:36:21
0:36:21
'Probabilistic scripts for automating common-sense tasks' by Alexander Lew
 0:20:40
0:20:40
ChatGPT 4 uses Bayesian Inference to predict Premier League! Part 1
 0:09:02
0:09:02
How To Automate Content Rewriting with WPeMatico GPT Spinner Addon
 0:00:26
0:00:26
Chat GPT code execution for probability distribution plot
 0:07:58
0:07:58
Large Language Models explained briefly
 0:17:40
0:17:40
(Vibe Coding 2023 Demo) My Dinner with GPT
![[LAFI'24] Effective Sequential](https://i.ytimg.com/vi/C1l9X7iXEiY/hqdefault.jpg) 0:11:27
0:11:27
[LAFI'24] Effective Sequential Monte Carlo for Language Model Probabilistic Programs
 1:10:07
1:10:07
Dr. JEFF BECK - The probability approach to AI
 0:00:14
0:00:14
DO NOT use ChatGPT - How to use AI to solve your maths problems ✅ #chatgpt #wolframalpha
 0:00:16
0:00:16
How I built my algo trading bot 💯 #algotrading #tradingbot #stockmarket #finance
 0:00:20
0:00:20
What is Machine Learning?? Dr Tanu Jain Interview #upscinterview #upscaspirants #shortsfeed #fypage
 0:21:14
0:21:14
GPT-4 Code Interpreter for Data Science - DEMO
 0:00:47
0:00:47
DeepSeek 671B params on Mac Studio
 0:36:00
0:36:00
Coding a Vision ChatGPT that plays Poker Autonomously! (GPT-4V Python tutorial)
 0:01:01
0:01:01
The Revolutionary Change in AI: GPT-o1 Explained
 1:25:35
1:25:35
Lecture 8, 2025; GPT, HMM, and Markov chains: Rollout variants for most likely sequence generation
 0:00:46
0:00:46
Three Perfect AI Tools for Data Analysis
 0:18:10
0:18:10
GPT like model inference sampling strategy
Комментарии