filmov
tv
What is LOAD BALANCING? ⚖️
Показать описание
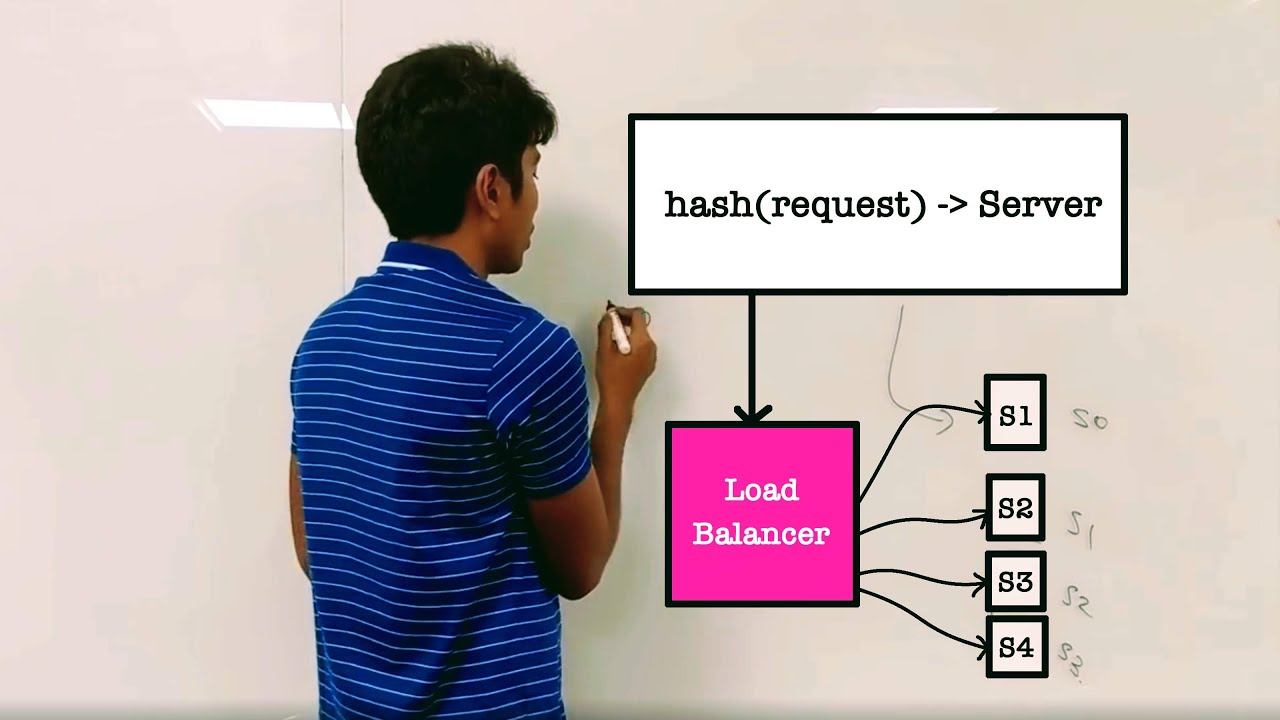
Load Balancing is a key concept in system design. One simple way would be hashing all requests and then sending them to the assigned server.
The standard way to hash objects is to map them to a search space and then transfer the load to the mapped computer. A system using this policy is likely to suffer when new nodes are added or removed from it.
One term you would hear in system design interviews is Fault Tolerance, in which case a machine crashes. And Scalability, in which devices must be added to process more requests. Another term used often is request allocation. This means assigning a request to a server.
Load balancing is often tied with service discovery and global locks. The type of load we want to balance is that of sticky sessions.
Looking to ace your next interview? Try this System Design video course! 🔥
00:00 Load Balancing - Consistent Hashing
00:33 Example
01:29 Server-Client Terms
02:12 Scaling
02:40 Load Balancing Problem
03:58 Hashing Requests
06:37 Request Stickiness
08:00 Splitting the Pie
10:35 Request Stickiness
13:29 Next Video!
With video lectures, architecture diagrams, capacity planning, API contracts, and evaluation tests. It's a complete package.
References:
System Design:
#LoadBalancer #Proxy #SystemDesign
The standard way to hash objects is to map them to a search space and then transfer the load to the mapped computer. A system using this policy is likely to suffer when new nodes are added or removed from it.
One term you would hear in system design interviews is Fault Tolerance, in which case a machine crashes. And Scalability, in which devices must be added to process more requests. Another term used often is request allocation. This means assigning a request to a server.
Load balancing is often tied with service discovery and global locks. The type of load we want to balance is that of sticky sessions.
Looking to ace your next interview? Try this System Design video course! 🔥
00:00 Load Balancing - Consistent Hashing
00:33 Example
01:29 Server-Client Terms
02:12 Scaling
02:40 Load Balancing Problem
03:58 Hashing Requests
06:37 Request Stickiness
08:00 Splitting the Pie
10:35 Request Stickiness
13:29 Next Video!
With video lectures, architecture diagrams, capacity planning, API contracts, and evaluation tests. It's a complete package.
References:
System Design:
#LoadBalancer #Proxy #SystemDesign
 0:08:22
0:08:22
What is a Load Balancer?
 0:01:13
0:01:13
What is Load Balancing?
 0:05:18
0:05:18
Top 6 Load Balancing Algorithms Every Developer Should Know
 0:04:42
0:04:42
Load Balancers for System Design Interviews
 0:02:58
0:02:58
What is Load Balancing? Benefits and Methods
 0:13:50
0:13:50
What is LOAD BALANCING? ⚖️
 0:09:28
0:09:28
System Design: What is Load Balancing?
 0:13:35
0:13:35
Load balancing - What is load balancing in networking | How load balancer works? (part#1)
 0:00:56
0:00:56
What is GLBP Gateway Load Balancing Protocol #learning #education #shorts #viral #facts #trending
 0:05:48
0:05:48
How Load Balancer Work with Animation | System Design Interview Basics
 0:42:42
0:42:42
you need to learn Load Balancing RIGHT NOW!! (and put one in your home network!)
 0:05:59
0:05:59
Load Balancing | Microservice
 0:06:35
0:06:35
Load Balancing - SY0-601 CompTIA Security+ : 3.3
 0:12:02
0:12:02
AWS Elastic Load Balancing Introduction
 0:05:08
0:05:08
What is Cloud Load Balancing?
 0:17:50
0:17:50
Load Balancer Tutorial - What is a Load Balancer
 0:03:23
0:03:23
What is a Load Balancer? | Lightboard Techtalk
 0:08:01
0:08:01
NetScaler Load Balancing, part 1
 0:37:33
0:37:33
Load balancing in Layer 4 vs Layer 7 with HAPROXY Examples
 0:01:03
0:01:03
What is Load Balancing?
 0:09:06
0:09:06
API Gateway vs Load Balancer vs Reverse Proxy: when to use what?
 0:10:11
0:10:11
Load Balancing | What are Load Balancers?
 0:02:49
0:02:49
What is Load balancing ? | What are Load Balancers ? | InterviewDOT
 0:02:51
0:02:51
The Load Balancing Problem
Комментарии