filmov
tv
Hướng Dẫn Các Bước Tiền Xử Lý Dữ Liệu bằng Scikit-Learn

Показать описание
Hướng Dẫn Các Bước Tiền Xử Lý Dữ Liệu bằng Scikit-Learn
Hello Diu Túp, hôm nay chúng mình xin giới thiệu đến các bạn 1 video mới trong Series "Tự Học Data Science Cho Người Mới Bắt Đầu". Và chủ đề của Video hôm này đó chính là "Hướng Dẫn Các Bước Tiền Xử Lý Dữ Liệu bằng Scikit-Learn" 🤩 !
Tiền xử lý dữ liệu (Data Pre-Processing) là một kỹ thuật được sử dụng để chuyển đổi dữ liệu thô thành một định dạng dễ hiểu. Dữ liệu trong thế giới thực (dữ liệu thô) luôn không đầy đủ và dữ liệu đó không thể được gửi qua các mô hình vì nó sẽ gây ra một số lỗi nhất định. Đó là lý do tại sao chúng ta cần xử lý trước dữ liệu trước khi gửi nó qua một mô hình.
⏱ Timestamps:
[0:00] Giới thiệu về Series "Tự Học Data Science Cho Người Mới Bắt Đầu"
[0:30] Giới thiệu về Nội Dung của Video
[5:00] Nhập các thư viện và Đọc tập dữ liệu
[8:00] Xử lý các giá trị bị thiếu (missing data replacement)
[20:30] Mã hoá các dữ liệu danh mục
[27:40] Cách tách dữ liệu (dataset) thành training và test sets
[40:00] Tiêu chuẩn hóa / Tỷ lệ tính năng (Feature Scaling)
------------- ✪ About CodeXplore Channel ✪ ------------
CodeXplore là một platform chia sẻ kiến thức về Lập Trình và Trí Tuệ Nhân Tạo (AI) dành cho các bạn trẻ Việt Nam.
Channel CodeXplore sẽ focus vào các chủ đề sau:
► Machine Learning (Máy Học) và Data Science (Khoa Học Dữ Liệu)
► Interview Preparation (Cấu Trúc Dữ Liệu và Thuật Toán & LeetCode Solutions)
► Lập Trình Python (Cơ Bản, Lập Trình Hướng Đối Tượng, Lập Trình Game)
------------------
➥ CodeXplore Social Links:
----------------------------------------------/-------------
© Bản quyền thuộc về CodeXplore
© Copyright by CodeXplore & Do not Reup
#MachineLearning #ScikitLearn #DataPreProcessing
Hello Diu Túp, hôm nay chúng mình xin giới thiệu đến các bạn 1 video mới trong Series "Tự Học Data Science Cho Người Mới Bắt Đầu". Và chủ đề của Video hôm này đó chính là "Hướng Dẫn Các Bước Tiền Xử Lý Dữ Liệu bằng Scikit-Learn" 🤩 !
Tiền xử lý dữ liệu (Data Pre-Processing) là một kỹ thuật được sử dụng để chuyển đổi dữ liệu thô thành một định dạng dễ hiểu. Dữ liệu trong thế giới thực (dữ liệu thô) luôn không đầy đủ và dữ liệu đó không thể được gửi qua các mô hình vì nó sẽ gây ra một số lỗi nhất định. Đó là lý do tại sao chúng ta cần xử lý trước dữ liệu trước khi gửi nó qua một mô hình.
⏱ Timestamps:
[0:00] Giới thiệu về Series "Tự Học Data Science Cho Người Mới Bắt Đầu"
[0:30] Giới thiệu về Nội Dung của Video
[5:00] Nhập các thư viện và Đọc tập dữ liệu
[8:00] Xử lý các giá trị bị thiếu (missing data replacement)
[20:30] Mã hoá các dữ liệu danh mục
[27:40] Cách tách dữ liệu (dataset) thành training và test sets
[40:00] Tiêu chuẩn hóa / Tỷ lệ tính năng (Feature Scaling)
------------- ✪ About CodeXplore Channel ✪ ------------
CodeXplore là một platform chia sẻ kiến thức về Lập Trình và Trí Tuệ Nhân Tạo (AI) dành cho các bạn trẻ Việt Nam.
Channel CodeXplore sẽ focus vào các chủ đề sau:
► Machine Learning (Máy Học) và Data Science (Khoa Học Dữ Liệu)
► Interview Preparation (Cấu Trúc Dữ Liệu và Thuật Toán & LeetCode Solutions)
► Lập Trình Python (Cơ Bản, Lập Trình Hướng Đối Tượng, Lập Trình Game)
------------------
➥ CodeXplore Social Links:
----------------------------------------------/-------------
© Bản quyền thuộc về CodeXplore
© Copyright by CodeXplore & Do not Reup
#MachineLearning #ScikitLearn #DataPreProcessing
 0:44:00
0:44:00
Hướng Dẫn Các Bước Tiền Xử Lý Dữ Liệu bằng Scikit-Learn
 0:11:09
0:11:09
Hướng Dẫn Tạo Kênh Youtube Kiếm Tiền Mới Nhất -/ Khỏi Làm Công Nhân
 0:12:57
0:12:57
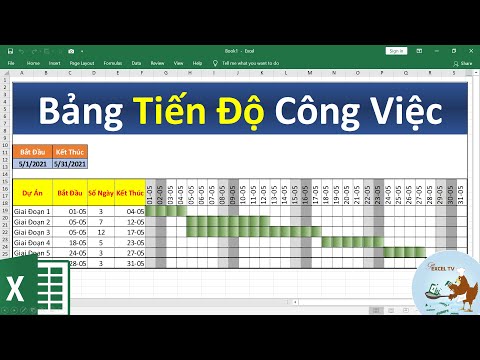
Hướng dẫn lập tiến độ công việc bằng excel (Vô cùng đơn giản)
 0:48:02
0:48:02
Hướng Dẫn Cách Lập Tiến Độ Thi Công Và Lập Kế Hoạch Nhân Lực Bằng Excel Cực Kỳ Chuyên Nghiệp...
 1:04:15
1:04:15
Hướng Dẫn Chi Tiết Nền Tảng Fiverr Dành Cho Người Mới Bắt Đầu | Công Việc Làm Thêm Cho Freelancer...
 0:47:50
0:47:50
P1: Bắt đầu | HƯỚNG DẪN ĐẦU TƯ CHỨNG KHOÁN CƠ BẢN, A-BỜ-CỜ ( TỪ A-Z )
 0:01:56
0:01:56
Hướng dẫn rút tiền bằng QR tại ATM của Vietcombank
 0:17:04
0:17:04
Hướng Dẫn Đặt Mục Tiêu 😎 Chất Miễn Bàn - Bài Học Kinh Doanh
 0:09:03
0:09:03
Hướng Dẫn Chạy Node Gradient Network | Dự Án DePIN Khủng Tiềm Năng X10 - X50
 0:40:19
0:40:19
Hướng Dẫn Giao Dịch Future Binance Trên Điện Thoại A - Z
 0:50:20
0:50:20
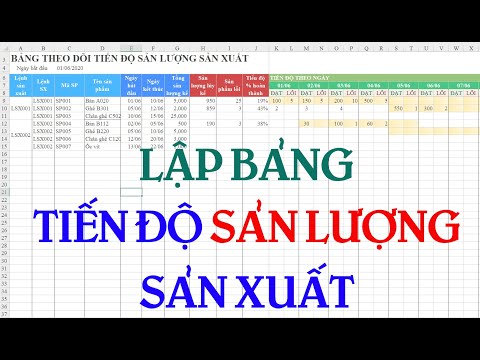
Hướng dẫn Lập bảng Tiến độ Sản lượng Sản xuất chi tiết dễ hiểu nhất
 0:39:25
0:39:25
Hướng Dẫn Keylogger Đơn Giản bằng Python | Lập Trình Gián Điệp Python
 0:12:50
0:12:50
TIẾT LỘ - HƯỚNG DẪN 5 kĩ thuật tráo bài đỉnh cao như 1 ảo thuật gia? TOP 5 | TrungKP...
 0:04:18
0:04:18
Pi network - Hướng dẫn KYC Pi chi tiết mới nhất duyệt trong 5 phút | PI NETWORK VN
 0:02:23
0:02:23
Hướng dẫn kỹ năng phòng ngự #2 I Kèm người
 0:35:25
0:35:25
Hướng Dẫn Đầu Tư Chứng Khoán Cơ Bản Từ A-Z (F0 phải biết) | Cú Thông Thái
 0:15:59
0:15:59
Excel cho người đi làm | #06 Hướng dẫn lập bảng theo dõi tiến độ công việc trên excel...
 0:01:34
0:01:34
HƯỚNG DẪN TẠO MÃ VÀ CHUYỂN TIỀN BẰNG MÃ QR TRÊN VCB DIGIBANK
 0:00:30
0:00:30
Hướng Dẫn Chuyển Tiền Ngay Trong Zalo
 0:07:19
0:07:19
Hướng dẫn tự vệ sinh MÁY LẠNH tại nhà với các bước cực dễ, ai cũng làm được!...
 0:12:58
0:12:58
Hướng Dẫn 6 Trò Ảo Thuật Tiền Hay Nhất Thế Giới
 0:02:02
0:02:02
Hướng dẫn cách chuyển tiền về Việt Nam siêu dễ!
 0:23:02
0:23:02
Hướng Dẫn Đầu Tư Tích Sản Vào Chứng Chỉ Quỹ ETF (A-Z) | Cú Thông Thái...
 0:06:31
0:06:31
Hướng dẫn kiếm tiền từ Youtube đơn giản?
Комментарии