filmov
tv
Smart City End to End Realtime Data Engineering Project | Get Hired as an AWS Data Engineer
Показать описание
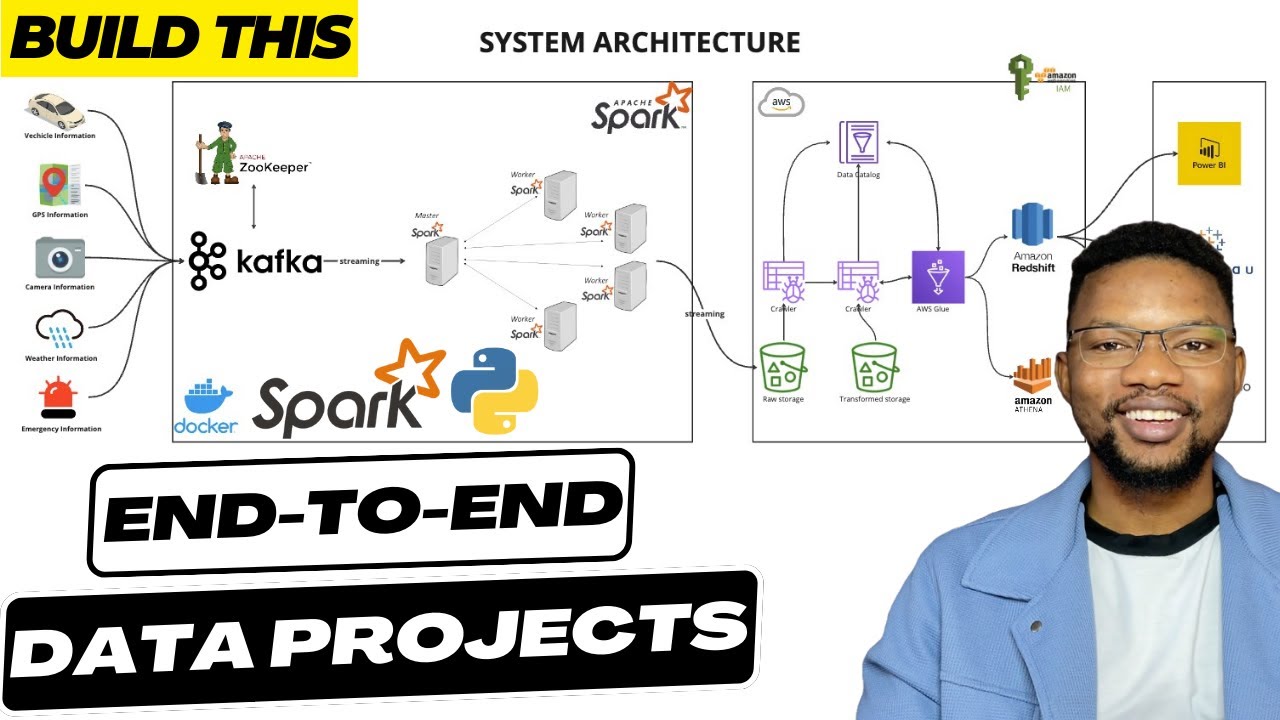
In this video, you will be building a Smart City End to End Realtime data streaming pipeline covering each phase from data ingestion to processing and finally storage. We'll utilize tools like IOT devices, Apache Zookeeper, Apache Kafka, Apache Spark, Docker, Python, AWS Cloud, AWS Glue, AWS Athena, AWS IAM, AWS Redshift and finally PowerBI to visualize data on Redshift.
Like this video?
Timestamps:
0:00 Introduction
1:29 System Architecture
7:22 Project Setup
9:00 Docker containers setup and coding
26:17 IOT services producer
38:19 Vehicle information Generator
48:10 GPS Information Generator
50:13 Traffic information Generator
53:13 Weather information Generator
58:35 Emergency Incident Generator
1:03:39 Producing IOT Data to Kafka
1:14:43 AWS S3 setup with policies
1:16:38 AWS IAM Roles and Credentials Management
1:19:14 Apache Spark Realtime Streaming from Kafka
2:01:14 Fixing Schema Issues in Apache Spark Structured Streaming
2:07:31 AWS Glue Crawlers
2:10:23 Working with AWS Athena
2:13:22 Loading Data into Redshift from AWS Glue Data Catalog
2:17:58 Connecting and Querying Redshift DW with DBeaver
2:20:51 Connecting Redshift to AWS Glue Catalog
2:23:34 Fixing IAM Permission issues with Redshift
2:26:05 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Data Engineering, Kafka, Apache Spark, Cassandra, PostgreSQL, Zookeeper, Docker, Docker Compose, ETL Pipeline, Data Pipeline, Big Data, Streaming Data, Real-time Analytics, Kafka Connect, Spark Master, Spark Worker, Schema Registry, Control Center, Data Streaming
✨ Hashtags ✨
#DataEngineering #Kafka #ApacheSpark #Cassandra #PostgreSQL #Docker #ETLPipeline #DataPipeline #StreamingData #RealTimeAnalytics
Like this video?
Timestamps:
0:00 Introduction
1:29 System Architecture
7:22 Project Setup
9:00 Docker containers setup and coding
26:17 IOT services producer
38:19 Vehicle information Generator
48:10 GPS Information Generator
50:13 Traffic information Generator
53:13 Weather information Generator
58:35 Emergency Incident Generator
1:03:39 Producing IOT Data to Kafka
1:14:43 AWS S3 setup with policies
1:16:38 AWS IAM Roles and Credentials Management
1:19:14 Apache Spark Realtime Streaming from Kafka
2:01:14 Fixing Schema Issues in Apache Spark Structured Streaming
2:07:31 AWS Glue Crawlers
2:10:23 Working with AWS Athena
2:13:22 Loading Data into Redshift from AWS Glue Data Catalog
2:17:58 Connecting and Querying Redshift DW with DBeaver
2:20:51 Connecting Redshift to AWS Glue Catalog
2:23:34 Fixing IAM Permission issues with Redshift
2:26:05 Outro
🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟
🔗 Useful Links and Resources:
✨ Tags ✨
Data Engineering, Kafka, Apache Spark, Cassandra, PostgreSQL, Zookeeper, Docker, Docker Compose, ETL Pipeline, Data Pipeline, Big Data, Streaming Data, Real-time Analytics, Kafka Connect, Spark Master, Spark Worker, Schema Registry, Control Center, Data Streaming
✨ Hashtags ✨
#DataEngineering #Kafka #ApacheSpark #Cassandra #PostgreSQL #Docker #ETLPipeline #DataPipeline #StreamingData #RealTimeAnalytics
 2:27:07
2:27:07
Smart City End to End Realtime Data Engineering Project | Get Hired as an AWS Data Engineer
 0:02:03
0:02:03
Smart City End to End Realtime Data Engineering Project | Get Hired as an AWS Data Engineer Full
 0:00:54
0:00:54
Smart City End to End Realtime Streaming - A Big Data Engineering Project
 0:01:22
0:01:22
Smart Cities - Better Places to Live
 0:07:14
0:07:14
Hewlett Packard Enterprise's End-to-End Surveillance Solution for Smart Cities| Digit.in
 0:03:19
0:03:19
AGIL® Smart City Operating System
 0:16:51
0:16:51
Smart City Project
 0:01:41
0:01:41
Edgeware End to End Smart City Solution-Integration of Custom Power Enclosures and Network is Key
 0:04:23
0:04:23
Latest Development Update 2025 | Sector A | Overseas Central | Current Prices | Capital Smart City
 0:08:39
0:08:39
Cloud Empowered Transformation for the Smart Cities of Tomorrow
 0:31:56
0:31:56
Unlocking possibilities for smart connected cities & spaces
 0:02:41
0:02:41
Collaborative Smart City Project: Juniper Networks and CENGN
 0:01:55
0:01:55
5G - Smart City & Privacy
 0:27:26
0:27:26
Why Smart Cities are Best Built Using Open Source, Open Standards and Open Data - Jim Craig, Red Hat
 0:04:35
0:04:35
Smart Cities Solution - Anacle Systems
 0:59:25
0:59:25
Smart Cities: Real IoT Use Cases
![[Atos Tech Days]](https://i.ytimg.com/vi/2MF8ldQsYU8/hqdefault.jpg) 0:24:14
0:24:14
[Atos Tech Days] Urban Platforms: From Smart Cities to Next Generation Connected Territories
 0:01:56
0:01:56
Smart City Assets Beyond Lighting
 0:25:26
0:25:26
Qualcomm Smart City Solutions: Digitization for IoT
 0:38:18
0:38:18
Smart City with Event Streaming and Apache Kafka
 0:56:20
0:56:20
How End-to-End IoT Connectivity Enables Smart Agriculture Solutions
 0:29:00
0:29:00
Webinar: Smart Cities
 0:03:53
0:03:53
COPA-DATA @Smart City Expo World Congress 2015 in Barcelona
 0:02:47
0:02:47
Oracle Smart Cities - Laying the bricks for tomorrow's cities
Комментарии