filmov
tv
'Workflows, a new abstraction for distributed systems' by Dominik Tornow (Strange Loop 2022)

Показать описание
For the past 45 years, the database systems community has enjoyed an unparalleled developer experience: Database Transactions mitigate challenges such as failure on a platform level, entirely eliminating these challenges on an applications level.
Unfortunately, the distributed systems community has not enjoyed a similar developer experience: There was no equivalent abstraction that mitigates challenges like failure on a platform level.
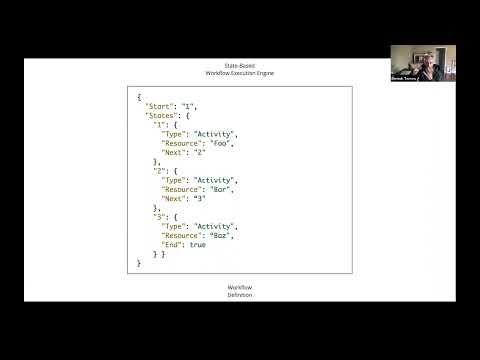
However, many companies, including Snap, Uber, and Netflix, are adopting a new paradigm: Workflows. Workflows are to distributed systems what transactions are to databases.
This talk explores how Workflow Systems mitigate challenges on a platform level and provide a developer experience for distributed systems that rivals the developer experience for databases, allowing you to literally code as if failure does not even exist!
Dominik Tornow
Temporal, Principal Engineer
@DominikTornow
Dominik Tornow is a Principal Engineer at Temporal. He focuses on systems modeling, specifically conceptual and formal modeling, to support the design and documentation of complex software systems.
------ Sponsored by: ------
Unfortunately, the distributed systems community has not enjoyed a similar developer experience: There was no equivalent abstraction that mitigates challenges like failure on a platform level.
However, many companies, including Snap, Uber, and Netflix, are adopting a new paradigm: Workflows. Workflows are to distributed systems what transactions are to databases.
This talk explores how Workflow Systems mitigate challenges on a platform level and provide a developer experience for distributed systems that rivals the developer experience for databases, allowing you to literally code as if failure does not even exist!
Dominik Tornow
Temporal, Principal Engineer
@DominikTornow
Dominik Tornow is a Principal Engineer at Temporal. He focuses on systems modeling, specifically conceptual and formal modeling, to support the design and documentation of complex software systems.
------ Sponsored by: ------
 0:38:55
0:38:55
'Workflows, a new abstraction for distributed systems' by Dominik Tornow (Strange Loop 202...
 0:06:58
0:06:58
Workflows, a new core abstraction for distributed systems - Dominik Tornow
 0:12:52
0:12:52
Workflow motif an abstraction for debugging distributed systems – Mania Abdi, NU
 0:05:40
0:05:40
KNIME Introduction Part 14 Workflow Abstraction
 0:24:33
0:24:33
SmolAgents: Build a Production-Ready Agent with Minimal Abstraction
 0:08:03
0:08:03
Automating lease abstraction for property management workflows
 0:25:56
0:25:56
LeitMotif: An Abstraction for Debugging Distributed Applications - Mania Abdi, Northeastern U
 0:17:31
0:17:31
Continuous Integration vs Feature Branch Workflow
 0:01:50
0:01:50
Abstraction and Orchestration in Cloud?
 0:11:24
0:11:24
Boston DevOps Meetup: Workflow Abstraction - Don Luchini
 0:36:08
0:36:08
Lesson 4: Modular Automation Through Abstraction
 0:05:12
0:05:12
FT006 - Abstraction Layers and the Foundry Era of Biotech R&D
 0:06:21
0:06:21
Abstract Part 2 | Branches, Sub-Branches & Libraries
 0:26:24
0:26:24
Waypoint: The Missing Abstraction between Devs and Deployments
 0:48:04
0:48:04
7 Use Cases in 7 Minutes Each : The Power of Workflows and Automation (SVC101) | AWS re:Invent 2013
 0:16:16
0:16:16
Master Contract Abstraction with AI: Transform Your Legal Operations | Botminds AI Case Study & ...
 0:43:14
0:43:14
Alegria group - Is AI the ultimate level of abstraction for NoCode?
 0:07:53
0:07:53
RPA- 10 Type of Solution Design and Abstraction Layers
 0:02:20
0:02:20
6 Essential Tips to Master Lease Abstraction and Maximize Accuracy | Springbord
 0:37:49
0:37:49
Robert J Berger - Higher Order Abstraction & Tooling for Step Functions & Serverless
 1:10:44
1:10:44
Francois Chollet | Why abstraction is the key to intelligence, and what we’re still missing
 0:31:37
0:31:37
Intro to Temporal Architecture: Workflow Engine
 0:05:18
0:05:18
#AskRaghav | How to explain your project in an interview | 5 Points |
 0:44:13
0:44:13
Modern Application Architectures
Комментарии