filmov
tv
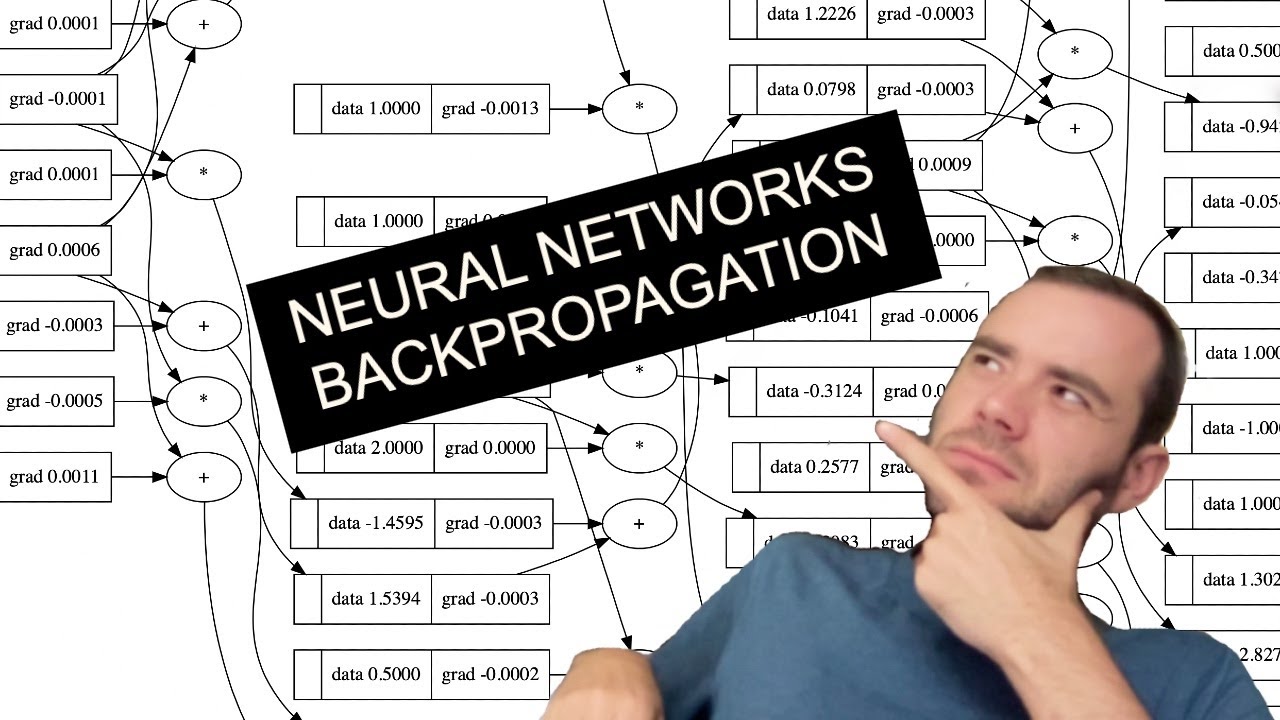
The spelled-out intro to neural networks and backpropagation: building micrograd
Показать описание
This is the most step-by-step spelled-out explanation of backpropagation and training of neural networks. It only assumes basic knowledge of Python and a vague recollection of calculus from high school.
Links:
- "discussion forum": nvm, use youtube comments below for now :)
Exercises:
you should now be able to complete the following google collab, good luck!:
Chapters:
00:00:00 intro
00:00:25 micrograd overview
00:08:08 derivative of a simple function with one input
00:14:12 derivative of a function with multiple inputs
00:19:09 starting the core Value object of micrograd and its visualization
00:32:10 manual backpropagation example #1: simple expression
00:51:10 preview of a single optimization step
00:52:52 manual backpropagation example #2: a neuron
01:09:02 implementing the backward function for each operation
01:17:32 implementing the backward function for a whole expression graph
01:22:28 fixing a backprop bug when one node is used multiple times
01:27:05 breaking up a tanh, exercising with more operations
01:39:31 doing the same thing but in PyTorch: comparison
01:43:55 building out a neural net library (multi-layer perceptron) in micrograd
01:51:04 creating a tiny dataset, writing the loss function
01:57:56 collecting all of the parameters of the neural net
02:01:12 doing gradient descent optimization manually, training the network
02:14:03 summary of what we learned, how to go towards modern neural nets
02:16:46 walkthrough of the full code of micrograd on github
02:21:10 real stuff: diving into PyTorch, finding their backward pass for tanh
02:24:39 conclusion
02:25:20 outtakes :)
Links:
- "discussion forum": nvm, use youtube comments below for now :)
Exercises:
you should now be able to complete the following google collab, good luck!:
Chapters:
00:00:00 intro
00:00:25 micrograd overview
00:08:08 derivative of a simple function with one input
00:14:12 derivative of a function with multiple inputs
00:19:09 starting the core Value object of micrograd and its visualization
00:32:10 manual backpropagation example #1: simple expression
00:51:10 preview of a single optimization step
00:52:52 manual backpropagation example #2: a neuron
01:09:02 implementing the backward function for each operation
01:17:32 implementing the backward function for a whole expression graph
01:22:28 fixing a backprop bug when one node is used multiple times
01:27:05 breaking up a tanh, exercising with more operations
01:39:31 doing the same thing but in PyTorch: comparison
01:43:55 building out a neural net library (multi-layer perceptron) in micrograd
01:51:04 creating a tiny dataset, writing the loss function
01:57:56 collecting all of the parameters of the neural net
02:01:12 doing gradient descent optimization manually, training the network
02:14:03 summary of what we learned, how to go towards modern neural nets
02:16:46 walkthrough of the full code of micrograd on github
02:21:10 real stuff: diving into PyTorch, finding their backward pass for tanh
02:24:39 conclusion
02:25:20 outtakes :)
 2:25:52
2:25:52
The spelled-out intro to neural networks and backpropagation: building micrograd
 0:18:40
0:18:40
But what is a neural network? | Chapter 1, Deep learning
 0:18:54
0:18:54
The Essential Main Ideas of Neural Networks
 0:13:14
0:13:14
Intro to Neural Networks : Data Science Concepts
 0:54:51
0:54:51
How to Create a Neural Network (and Train it to Identify Doodles)
 0:12:10
0:12:10
Code It From Scratch: Neural Networks
 0:07:00
0:07:00
Gentle Intro To Neural Nets #10 Neural network class definition
 0:13:29
0:13:29
Introduction | Neural Networks from The Ground Up [Python]
 0:06:23
0:06:23
What Are Activation Functions in Deep Learning?
 1:13:59
1:13:59
Lecture 4 | Introduction to Neural Networks
 0:02:44
0:02:44
Neural Networks From Scratch - Course Intro and Curriculum
 1:26:39
1:26:39
2022-12-12 PRML - Intro to Neural Networks
 0:10:04
0:10:04
Beginner Intro to Neural Networks 8: Linear Regression
 1:13:07
1:13:07
20: Hopfield Networks - Intro to Neural Computation
 0:17:38
0:17:38
Neural Networks Explained from Scratch using Python
 0:15:07
0:15:07
How to explain Graph Neural Networks (with XAI)
 0:05:52
0:05:52
Deep Learning | What is Deep Learning? | Deep Learning Tutorial For Beginners | 2023 | Simplilearn
 0:13:52
0:13:52
The Neural Network, A Visual Introduction
 0:10:30
0:10:30
Why Neural Networks can learn (almost) anything
 0:16:59
0:16:59
Intro to neural networks
 0:04:45
0:04:45
Artificial Neural Networks explained
 0:32:24
0:32:24
Introduction to Artificial Neural Networks & Bias
 0:06:48
0:06:48
Backpropagation in Neural Networks | Back Propagation Algorithm with Examples | Simplilearn
 0:26:54
0:26:54
Deep Learning Lecture 1.3 - Intro Neural Networks
Комментарии