filmov
tv
Observability of Distributed Systems (class SRE implements DevOps)

Показать описание
In their previous video, Liz and Seth reduced actionable alerts by focusing on Service Level Objectives (SLOs), but how can we make our systems observable, instead of only being able to debug what we've thought to monitor in the past?
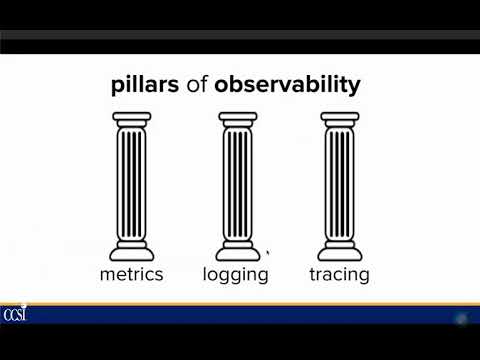
In this video, you learn how structured logs, metrics, and traces help SRE and DevOps practitioners find out where the systems are broken. We'll use metrics to find slow or erroring queries, traces to find interactions between components, and logs to understand the errors in more detail.
To get started with this functionality, Google Cloud offers Stackdriver Service Monitoring.
Reference Links:
Reach out to Liz and Seth:
In this video, you learn how structured logs, metrics, and traces help SRE and DevOps practitioners find out where the systems are broken. We'll use metrics to find slow or erroring queries, traces to find interactions between components, and logs to understand the errors in more detail.
To get started with this functionality, Google Cloud offers Stackdriver Service Monitoring.
Reference Links:
Reach out to Liz and Seth:
 0:04:58
0:04:58
 0:38:16
0:38:16
 0:10:24
0:10:24
 0:33:10
0:33:10
 1:01:51
1:01:51
 1:07:45
1:07:45
 0:43:40
0:43:40
 0:01:52
0:01:52
 0:52:35
0:52:35
 0:41:02
0:41:02
 0:54:03
0:54:03
 0:48:33
0:48:33
 0:37:26
0:37:26
 0:23:52
0:23:52
 0:00:58
0:00:58
 0:13:39
0:13:39
 0:53:15
0:53:15
 0:24:31
0:24:31
 0:07:02
0:07:02
 0:00:51
0:00:51
 0:29:19
0:29:19
 0:28:14
0:28:14
 0:04:27
0:04:27
 0:21:30
0:21:30