filmov
tv
Read Large Dataset Quickly - Feather vs Parquet vs Jay vs CSV #python #pandas #coding #programming

Показать описание
We generally prefer CSV files to read data for Data science stuff. But While dealing with large datasets like millions of rows, CSV file format outperforms. It takes quite a long time to load the data. Some other file formats also exist that work well while dealing with large datasets.
Some Efficient File Format:-
Feather format - It is fast, lightweight, and uses binary file format for storing data. It takes 122 milliseconds to read One million rows.
Parquet format - Parquet is more efficient in terms of storage and performance. whereas data is stored in a row-oriented approach. And it takes 159 milliseconds to read 1 million row
Jay format - It also uses a binary format for storing data frames and because of that it is fast, lightweight, and easy-to-use. And it takes only 235 microseconds, which is the least of all.
#leetcode #codingchallenge #technology #tech
Show your support by subscribing to my channel.
Thank you
Some Efficient File Format:-
Feather format - It is fast, lightweight, and uses binary file format for storing data. It takes 122 milliseconds to read One million rows.
Parquet format - Parquet is more efficient in terms of storage and performance. whereas data is stored in a row-oriented approach. And it takes 159 milliseconds to read 1 million row
Jay format - It also uses a binary format for storing data frames and because of that it is fast, lightweight, and easy-to-use. And it takes only 235 microseconds, which is the least of all.
#leetcode #codingchallenge #technology #tech
Show your support by subscribing to my channel.
Thank you
 0:07:05
0:07:05
How to process large dataset with pandas | Avoid out of memory issues while loading data into pandas
 0:05:50
0:05:50
From 2.5 million row reads to 1 (optimizing my database performance)
 0:21:12
0:21:12
Generate Data Science/Data Analysis Report of your DataSet in 5 Minutes
 0:15:40
0:15:40
How to train a ML model on a dataset with 3 crore rows?
 0:09:06
0:09:06
Read Large Data from Excel or CSV to Database TIBCO
 0:09:44
0:09:44
Read millions of records from database using Java/Jdbc
 0:17:24
0:17:24
2 ways to reduce your Power BI dataset size and speed up refresh
 0:08:42
0:08:42
7 Must-know Strategies to Scale Your Database
 0:35:17
0:35:17
Scaling Ray Train to 10K Kubernetes Nodes on GKE | Ray Summit 2024
 0:08:12
0:08:12
5 Secrets for making PostgreSQL run BLAZING FAST. How to improve database performance.
 0:04:51
0:04:51
Normalize JSON Dataset With pandas
 0:08:41
0:08:41
MYSQL Tutorial: Efficiently Importing Large CSV Files into MySQL Database with LOAD DATA INFILE
 0:05:12
0:05:12
Big Data In 5 Minutes | What Is Big Data?| Big Data Analytics | Big Data Tutorial | Simplilearn
 0:09:46
0:09:46
How to Read Dataset in Google Colab from Google Drive
 0:17:01
0:17:01
Google BigQuery: Work with Huge Datasets in Python
 0:09:53
0:09:53
7 Database Paradigms
 0:11:21
0:11:21
Loading, Viewing, working with an R dataset (basics)
 0:10:20
0:10:20
A Beginners Guide To The Data Analysis Process
 0:07:04
0:07:04
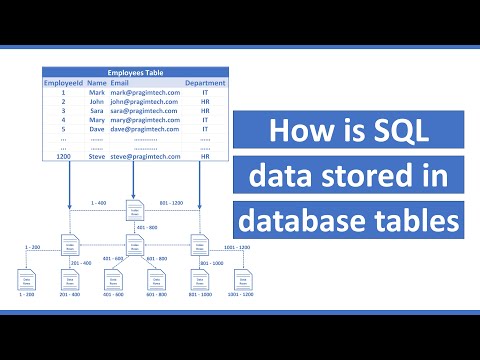
How is data stored in sql database
 0:03:39
0:03:39
What is a Columnar Database?
 0:43:31
0:43:31
How To Clip NetCDF Dataset By Shapefile Using Python Script
 0:11:32
0:11:32
How to divide the large dataset into folders with each folder containing a class based on csv python
 0:08:08
0:08:08
Load Image Dataset using OpenCV | Computer Vision | Machine Learning | Data Magic
 0:05:22
0:05:22
Database vs Data Warehouse vs Data Lake | What is the Difference?
Комментарии