filmov
tv
A Deep Learning Approach to Traffic Accident Prediction on Heterogeneous Spatio-Temporal Data
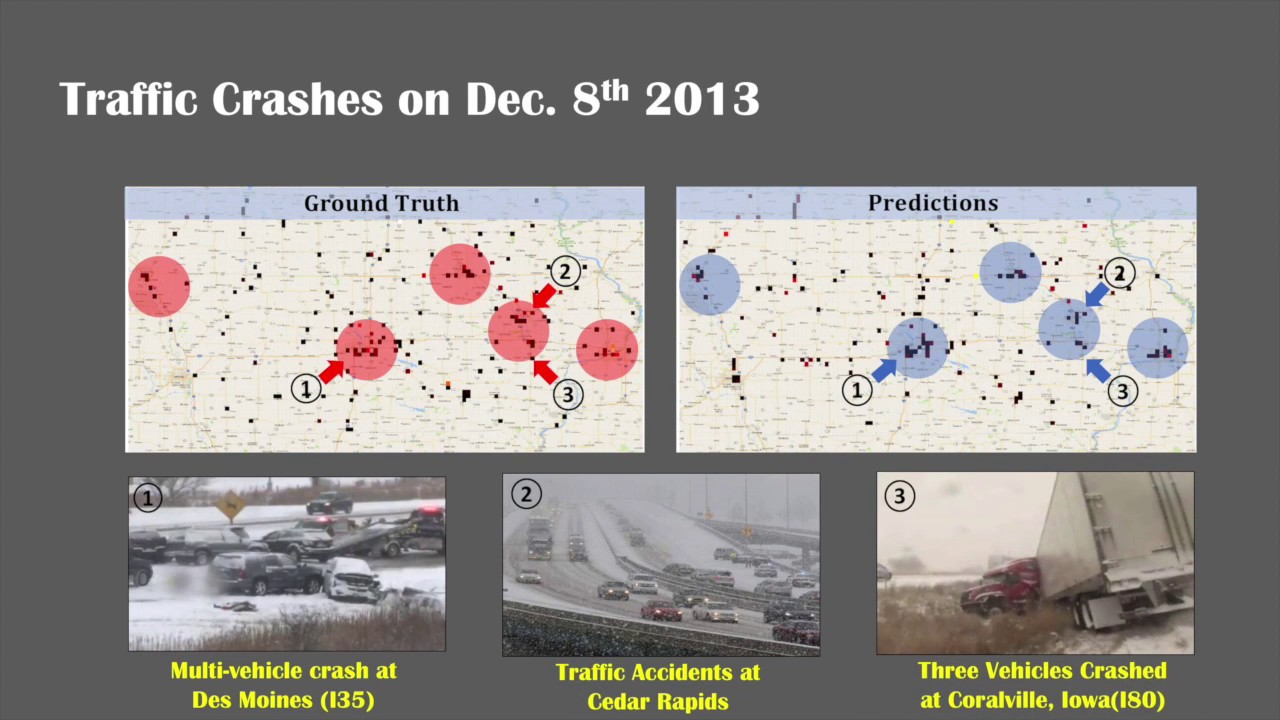
Показать описание
Hetero-ConvLSTM: A Deep Learning Approach to Traffic Accident Prediction on Heterogeneous Spatio-Temporal Data
Authors:
Zhuoning Yuan (University of Iowa); Xun Zhou (University of Iowa); Tianbao Yang (University of Iowa)
Abstract:
Predicting traffic accidents is a crucial problem to improving transportation and public safety as well as safe routing. The problem is also challenging due to the rareness of accidents in space and time and spatial heterogeneity of the environment (e.g., urban vs. rural). Most previous research on traffic accident prediction conducted by domain researchers simply applied classical prediction models on limited data without addressing the above challenges properly, thus leading to unsatisfactory performance. A small number of recent works have attempted to use deep learning for traffic accident prediction. However, they either ignore time information or use only data from a small and homogeneous study area (a city), without handling spatial heterogeneity and temporal auto-correlation properly at the same time.
In this paper we perform a comprehensive study on the traffic accident prediction problem using the Convolutional Long Short-Term Memory (ConvLSTM) neural network model. A number of detailed features such as weather, environment, road condition, and traffic volume are extracted from big datasets over the state of Iowa across 8 years. To address the spatial heterogeneity challenge in the data, we propose a Hetero-ConvLSTM framework, where a few novel ideas are implemented on top of the basic ConvLSTM model, such as incorporating spatial graph features and spatial model ensemble. Extensive experiments on the 8-year data over the entire state of Iowa show that the proposed framework makes reasonably accurate predictions and significantly improves the prediction accuracy over baseline approaches.
Authors:
Zhuoning Yuan (University of Iowa); Xun Zhou (University of Iowa); Tianbao Yang (University of Iowa)
Abstract:
Predicting traffic accidents is a crucial problem to improving transportation and public safety as well as safe routing. The problem is also challenging due to the rareness of accidents in space and time and spatial heterogeneity of the environment (e.g., urban vs. rural). Most previous research on traffic accident prediction conducted by domain researchers simply applied classical prediction models on limited data without addressing the above challenges properly, thus leading to unsatisfactory performance. A small number of recent works have attempted to use deep learning for traffic accident prediction. However, they either ignore time information or use only data from a small and homogeneous study area (a city), without handling spatial heterogeneity and temporal auto-correlation properly at the same time.
In this paper we perform a comprehensive study on the traffic accident prediction problem using the Convolutional Long Short-Term Memory (ConvLSTM) neural network model. A number of detailed features such as weather, environment, road condition, and traffic volume are extracted from big datasets over the state of Iowa across 8 years. To address the spatial heterogeneity challenge in the data, we propose a Hetero-ConvLSTM framework, where a few novel ideas are implemented on top of the basic ConvLSTM model, such as incorporating spatial graph features and spatial model ensemble. Extensive experiments on the 8-year data over the entire state of Iowa show that the proposed framework makes reasonably accurate predictions and significantly improves the prediction accuracy over baseline approaches.
 0:05:52
0:05:52
Deep Learning | What is Deep Learning? | Deep Learning Tutorial For Beginners | 2023 | Simplilearn
 0:07:50
0:07:50
Machine Learning vs Deep Learning
 0:07:52
0:07:52
Machine Learning | What Is Machine Learning? | Introduction To Machine Learning | 2024 | Simplilearn
 0:06:27
0:06:27
Supervised vs Unsupervised vs Reinforcement Learning | Machine Learning Tutorial | Simplilearn
 0:04:42
0:04:42
Deep Clustering: A Deep Learning Approach for High-Dimensional Data Clustering
 0:05:49
0:05:49
AI vs Machine Learning
 0:04:18
0:04:18
A Deep Learning Approach for Generalized Speech Animation
 0:36:33
0:36:33
TRR181 Seminar Series: 'A deep learning approach to extract internal tides....', by Han Wa...
 0:24:51
0:24:51
Deep Learning based Blood Group Detection using Fingerprint | Python Machine Learning IEEE Project
 0:02:55
0:02:55
Deep Learning: Long Short-Term Memory Networks (LSTMs)
 0:02:38
0:02:38
Machine Learning for Drug Discovery (Explained in 2 minutes)
 0:43:12
0:43:12
'The Machine Learning Approach' by Michael Kearns
 0:11:27
0:11:27
How to approach any machine learning problem | Step by Step approach for a machine learning problem
 0:05:45
0:05:45
Neural Network In 5 Minutes | What Is A Neural Network? | How Neural Networks Work | Simplilearn
 1:27:41
1:27:41
Deep Learning State of the Art (2020)
 0:00:59
0:00:59
Deep Learning vs. Machine Learning, which is better?
 0:08:48
0:08:48
Machine Learning FOR BEGINNERS - Supervised, Unsupervised and Reinforcement Learning
 0:02:48
0:02:48
Classification and Regression in Machine Learning
 0:14:50
0:14:50
AI vs Machine Learning vs Deep Learning | AI vs ML vs DL - Differences Explained | Edureka
 0:28:54
0:28:54
Deep Learning Approach for Extreme Multi-label Text Classification
 0:12:31
0:12:31
7 best machine learning books in 2022
 0:20:33
0:20:33
Gradient descent, how neural networks learn | Chapter 2, Deep learning
 0:26:56
0:26:56
Deep Learning to Discover Coordinates for Dynamics: Autoencoders & Physics Informed Machine Lear...
 0:00:47
0:00:47
Tons of Machine Learning FEATURE data? Try this!
Комментарии