filmov
tv
Ψεύτικη ομιλία από «συνθετικό» Ομπάμα σε βίντεο, μέσω εργαλείου τεχνητής νοημοσύνης

Показать описание
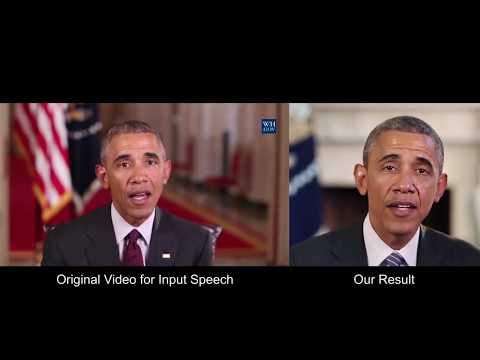
Συνθέτοντας τον Ομπάμα: Μάθηση του Συγχρονισμού χειλιών από τον Ήχο.
Δίδοντας τον ήχο ομιλίας του Προέδρου Μπαράκ Ομπάμα, συνθέσαμε ένα βίντεο υψηλής ποιότητας από ομιλία του με ακριβή συγχρονισμό με τα χείλη του, δημιουργώντας ένα στοχευμένο βίντεο κλιπ.
Εκπαιδεύτηκε πολλές ώρες εβδομαδιαία στα λήμματα του, ένα επαναλαμβανόμενο νευρωνικό δίκτυο μαθαίνει τη χαρτογράφηση από ακατέργαστα χαρακτηριστικά ήχου σε σχήματα στόματος. Δεδομένου του σχήματος του στόματος κάθε στιγμή, συνθέσαμε υφή υψηλής ποιότητας στο στόμα και το δημιουργήσαμε με το κατάλληλο τρισδιάστατο ταίριασμα, αλλάζοντας αυτό που φαίνεται να λέει σε ένα βίντεο προορισμού ώστε να ταιριάζει με τον ήχο εισόδου.
(Ελεύθερη μετάφραση από ΕΛΕΥΘΕΡΟΙ ΕΛΛΗΝΕΣ)
Synthesizing Obama: Learning Lip Sync from Audio
Supasorn Suwajanakorn, Steven M. Seitz, Ira Kemelmacher-Shlizerman
SIGGRAPH 2017
Given audio of President Barack Obama, we synthesize a high quality video of him speaking with accurate lip sync, composited into a target video clip. Trained on many hours of his weekly address footage, a recurrent neural network learns the mapping from raw audio features to mouth shapes. Given the mouth shape at each time instant, we synthesize high quality mouth texture, and composite it with proper 3D pose matching to change what he appears to be saying in a target video to match the input audio track
Αρχική πηγή βίντεο από τον χρήστη: Supasorn Suwajanakorn
Δίδοντας τον ήχο ομιλίας του Προέδρου Μπαράκ Ομπάμα, συνθέσαμε ένα βίντεο υψηλής ποιότητας από ομιλία του με ακριβή συγχρονισμό με τα χείλη του, δημιουργώντας ένα στοχευμένο βίντεο κλιπ.
Εκπαιδεύτηκε πολλές ώρες εβδομαδιαία στα λήμματα του, ένα επαναλαμβανόμενο νευρωνικό δίκτυο μαθαίνει τη χαρτογράφηση από ακατέργαστα χαρακτηριστικά ήχου σε σχήματα στόματος. Δεδομένου του σχήματος του στόματος κάθε στιγμή, συνθέσαμε υφή υψηλής ποιότητας στο στόμα και το δημιουργήσαμε με το κατάλληλο τρισδιάστατο ταίριασμα, αλλάζοντας αυτό που φαίνεται να λέει σε ένα βίντεο προορισμού ώστε να ταιριάζει με τον ήχο εισόδου.
(Ελεύθερη μετάφραση από ΕΛΕΥΘΕΡΟΙ ΕΛΛΗΝΕΣ)
Synthesizing Obama: Learning Lip Sync from Audio
Supasorn Suwajanakorn, Steven M. Seitz, Ira Kemelmacher-Shlizerman
SIGGRAPH 2017
Given audio of President Barack Obama, we synthesize a high quality video of him speaking with accurate lip sync, composited into a target video clip. Trained on many hours of his weekly address footage, a recurrent neural network learns the mapping from raw audio features to mouth shapes. Given the mouth shape at each time instant, we synthesize high quality mouth texture, and composite it with proper 3D pose matching to change what he appears to be saying in a target video to match the input audio track
Αρχική πηγή βίντεο από τον χρήστη: Supasorn Suwajanakorn
 0:08:01
0:08:01
 0:01:31
0:01:31
 0:01:10
0:01:10
 0:03:48
0:03:48
 0:02:01
0:02:01
 0:00:43
0:00:43
 0:01:20
0:01:20
 0:12:09
0:12:09
 0:01:49
0:01:49
 0:01:36
0:01:36
 0:04:11
0:04:11
 0:03:20
0:03:20
 0:03:12
0:03:12
 0:01:32
0:01:32
 0:10:30
0:10:30
 0:04:13
0:04:13