filmov
tv
How to Use AWS Textract API for Extracting Text and Data from Documents - Python (2025)

Показать описание
Looking to extract text and data from documents using AWS Textract? 📝 In this video, we’ll walk you through the process of using the AWS Textract API to extract text, tables, and structured data from scanned documents, PDFs, and images. This tutorial is perfect for developers, businesses, and data analysts looking to automate document processing with the power of machine learning.
### **What You’ll Learn in This Video:**
1️⃣ **What is AWS Textract?** A quick introduction to AWS Textract and its features for text and data extraction.
2️⃣ **Setting Up Your AWS Environment:** Learn how to configure AWS Textract in your account, including IAM roles and permissions.
3️⃣ **Installing the AWS SDK:** Set up the AWS SDK for Python (Boto3) to interact with the Textract API.
4️⃣ **Extracting Text with Textract:** Use the Textract API to extract text and data from documents.
5️⃣ **Working with Key-Value Pairs and Tables:** Learn how to extract structured data like forms and tables.
6️⃣ **Practical Demo:** Watch as we walk through a hands-on coding example for processing a sample document.
### **Why Use AWS Textract?**
AWS Textract uses advanced machine learning to extract text and structured data automatically, saving time and reducing errors compared to manual data entry. It supports a variety of use cases, including processing invoices, forms, legal documents, and more.
### **Who Is This Tutorial For?**
- Developers integrating document processing into their applications.
- Businesses automating document workflows.
- Data analysts working with scanned or digital documents.
### **Resources Mentioned in the Video:**
- Sample Code (GitHub): [Link to GitHub repo, if applicable]
### **Key Commands and Code Snippets Covered:**
- Installing Boto3:
```bash
pip install boto3
```
- Sample Code for Text Extraction:
```python
import boto3
for block in response['Blocks']:
if block['BlockType'] == 'LINE':
print(block['Text'])
```
### **Pro Tips for AWS Textract Success:**
✅ Ensure your documents are clear and high-quality for better results.
✅ Use S3 for large document storage and process them directly with Textract.
✅ Leverage Textract’s features like key-value pair detection for automating form processing.
### **Don’t Forget to Subscribe!**
If this tutorial helped you, give it a like, share it with your team, and subscribe for more AWS tutorials and machine learning content. Got questions? Drop them in the comments, and we’ll answer them in our next video!
### **Hashtags:**
#AWSTextract #MachineLearning #DocumentProcessing #DataExtraction #AWS #APITutorial #Python #Boto3 #TechTutorial #Automation
Unlock the power of AWS Textract and streamline your document processing workflows today! 🚀📄
### **What You’ll Learn in This Video:**
1️⃣ **What is AWS Textract?** A quick introduction to AWS Textract and its features for text and data extraction.
2️⃣ **Setting Up Your AWS Environment:** Learn how to configure AWS Textract in your account, including IAM roles and permissions.
3️⃣ **Installing the AWS SDK:** Set up the AWS SDK for Python (Boto3) to interact with the Textract API.
4️⃣ **Extracting Text with Textract:** Use the Textract API to extract text and data from documents.
5️⃣ **Working with Key-Value Pairs and Tables:** Learn how to extract structured data like forms and tables.
6️⃣ **Practical Demo:** Watch as we walk through a hands-on coding example for processing a sample document.
### **Why Use AWS Textract?**
AWS Textract uses advanced machine learning to extract text and structured data automatically, saving time and reducing errors compared to manual data entry. It supports a variety of use cases, including processing invoices, forms, legal documents, and more.
### **Who Is This Tutorial For?**
- Developers integrating document processing into their applications.
- Businesses automating document workflows.
- Data analysts working with scanned or digital documents.
### **Resources Mentioned in the Video:**
- Sample Code (GitHub): [Link to GitHub repo, if applicable]
### **Key Commands and Code Snippets Covered:**
- Installing Boto3:
```bash
pip install boto3
```
- Sample Code for Text Extraction:
```python
import boto3
for block in response['Blocks']:
if block['BlockType'] == 'LINE':
print(block['Text'])
```
### **Pro Tips for AWS Textract Success:**
✅ Ensure your documents are clear and high-quality for better results.
✅ Use S3 for large document storage and process them directly with Textract.
✅ Leverage Textract’s features like key-value pair detection for automating form processing.
### **Don’t Forget to Subscribe!**
If this tutorial helped you, give it a like, share it with your team, and subscribe for more AWS tutorials and machine learning content. Got questions? Drop them in the comments, and we’ll answer them in our next video!
### **Hashtags:**
#AWSTextract #MachineLearning #DocumentProcessing #DataExtraction #AWS #APITutorial #Python #Boto3 #TechTutorial #Automation
Unlock the power of AWS Textract and streamline your document processing workflows today! 🚀📄
 0:08:17
0:08:17
How to Use AWS Textract API for Extracting Text and Data from Documents - Python (2025)
 0:03:12
0:03:12
AWS Textract Demo
 0:08:17
0:08:17
Using Amazon Textract Custom Queries to Analyze Text Documents | Amazon Web Services
 0:01:50
0:01:50
What is Amazon Textract?
 0:03:01
0:03:01
Amazon Textract: 7 Things You GOT To Know 🧐 | AWS
 0:20:06
0:20:06
AWS Textract tutorial, Extract Forms, Tables from Image using Python
 0:24:08
0:24:08
AWS Project: Amazon Textract, Comprehend and Bedrock EXPLAINED: Hands-On Tutorial for Beginners
 0:08:35
0:08:35
Amazon Textract - Extracting text, tables and forms from documents
 0:30:55
0:30:55
How to Extract Text from PDFs and Images with Amazon Textract | OCR | NLP | Python Code | AWS
 0:00:06
0:00:06
Amazon Textract: Easily extract text and data from virtually any document
 0:13:10
0:13:10
Machine Learning - AWS Textract
 0:06:25
0:06:25
How to use AWS Textract to extract plain text from an image or a document
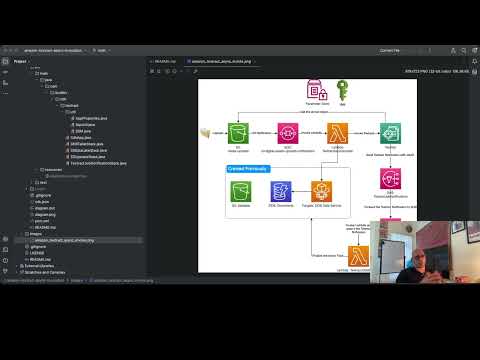 0:06:23
0:06:23
Build your first Amazon Textract application | Use CDK to create the AWS resources
 0:00:21
0:00:21
Amazon Textract Tutorial: Extract Data From Documents Easily!
 0:07:45
0:07:45
AWS Textract Demo Convert Images to Text & Application for Easier use
 0:07:56
0:07:56
AWS Textract API for Images - AWS Textract OCR Tutorial: Text Extraction with Python
 0:34:44
0:34:44
Getting Started With AWS Document AI Textract API In Python | AWS Cloud Tutorial
 0:18:05
0:18:05
AWS Tutorial - Amazon Textract - Overview & Demo
 0:05:49
0:05:49
AWS Textract - Python Set Up
 0:02:34
0:02:34
AWS Textract OCR Using Lambda and S3
 0:14:50
0:14:50
How to Extract Information from Document/Images Using AWS Textract Service
 0:00:58
0:00:58
47. AI Powered Invoice Extraction with AWS Textract | Automate Your Workflow in Seconds!
 0:16:44
0:16:44
AWS CLI Textract
 0:02:36
0:02:36
Serverless application : PDF/Image document parsing using AWS Textract and Lambda
Комментарии