filmov
tv
Regression forecasting and predicting - Practical Machine Learning Tutorial with Python p.5

Показать описание
In this video, make sure you define the X's like so. I flipped the last two lines by mistake:
X_lately = X[-forecast_out:]
X = X[:-forecast_out:]
In many cases, you wont be able to do this. Imagine if you were using gigabytes of data to train a classifier. It may take days to train your classifier, you wouldn't want to be doing this every...single...time you wanted to make a prediction. Thus, you may need to either NOT scale anything, or you may scale the data separately. As usual, you will want to test both options and see which is best in your specific case.
With that in mind, let's handle all of the rows from the definition of X onward.
X_lately = X[-forecast_out:]
X = X[:-forecast_out:]
In many cases, you wont be able to do this. Imagine if you were using gigabytes of data to train a classifier. It may take days to train your classifier, you wouldn't want to be doing this every...single...time you wanted to make a prediction. Thus, you may need to either NOT scale anything, or you may scale the data separately. As usual, you will want to test both options and see which is best in your specific case.
With that in mind, let's handle all of the rows from the definition of X onward.
 0:14:28
0:14:28
Regression forecasting and predicting - Practical Machine Learning Tutorial with Python p.5
 0:04:23
0:04:23
Linear Regression in Excel: How to Interpret a Model & Make Predictions
 0:04:12
0:04:12
Regression Method of Forecasting Using Microsoft Excel
 0:02:34
0:02:34
Linear Regression in 2 minutes
 0:03:33
0:03:33
using regression equation for predictions
 0:12:44
0:12:44
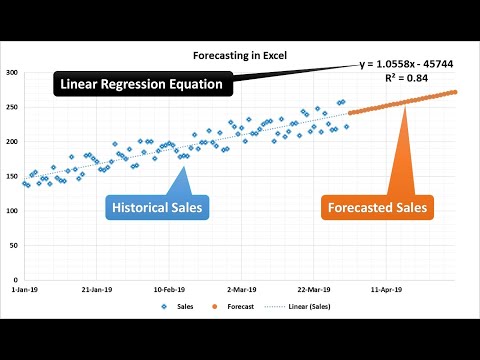
Forecasting in Excel using Linear Regression
 0:06:36
0:06:36
Forecasting and Regression Analysis in Excel
 0:03:38
0:03:38
Linear Regression Models: Prediction Using Regression
 0:00:32
0:00:32
Chapter 1: Regression | ML | AI
 0:45:17
0:45:17
Regression Analysis | Full Course
 0:09:38
0:09:38
Regression Analysis: An introduction to Linear and Logistic Regression
 0:09:40
0:09:40
Foundational Regression – Using Regression for Prediction (14-3)
 0:10:31
0:10:31
PREDICT THE FUTURE with LINEAR REGRESSION / How to use LINEST function / Beginners Guide to Power BI
 0:15:00
0:15:00
Predicting a Stock Price Using Regression
 0:10:00
0:10:00
Netflix Revenue Forecasting Regression Model
 0:04:45
0:04:45
Regression: Prediction and Extrapolation
 0:23:09
0:23:09
Time Series Forecasting with XGBoost - Use python and machine learning to predict energy consumption
 0:08:11
0:08:11
How To... Make a Prediction using a Multiple Linear Regression Model in R #102
 0:20:48
0:20:48
W4: P1: Predict the Future: Mastering Linear Regression Models for Accurate Forecasting!
 0:03:59
0:03:59
Stata 2023: Prediction (Forecasting) After Linear Regression
 0:10:53
0:10:53
Machine Learning: Python Simple Linear Regression | Predict future sales | Predictive Analytics
 0:07:29
0:07:29
What is Time Series Analysis?
 0:01:53
0:01:53
Excel Magic Trick 1046: Linear Regression Estimate & Add Many Predicted Y-Values Single Cell For...
 0:24:23
0:24:23
Forecasting Future Sales Using ARIMA and SARIMAX
Комментарии