filmov
tv
INTRODUCTION TO BIG DATA WITH PYSPARK - COLLABORATIVE FILTERING

Показать описание
Welcome to the SupderDataScience series on PySpark! Looking to learn more about Big Data and Machine Learning? Want to dive into projects using Python and Spark to harness the power of cloud computing? Get started with this incredible series that will progress to more complicated Pyspark tutorials to assist in providing you the knowledge and tools you need to create ground-breaking projects and big data algorithms. PySpark is a Python API built on Apache Spark which is an open-source cluster-computing framework. Big data operations are crucial from operations in Artificial Intelligence, Data Science to Cyber Security and much more. Get started learning today!
 0:05:12
0:05:12
Big Data In 5 Minutes | What Is Big Data?| Big Data Analytics | Big Data Tutorial | Simplilearn
 0:11:23
0:11:23
Intro to Big Data: Crash Course Statistics #38
 0:01:49
0:01:49
What is Big Data | Big Data in 2 Minutes | Introduction to Big Data | Big Data Training | Edureka
 0:06:21
0:06:21
Hadoop In 5 Minutes | What Is Hadoop? | Introduction To Hadoop | Hadoop Explained |Simplilearn
 0:08:20
0:08:20
Introduction to Big Data Analytics 🔥
 0:01:50
0:01:50
What Is Big Data?
 0:12:45
0:12:45
Lec-128: Introduction to BIG Data in Hindi | Small Data Vs BIG Data | Real Life Examples
 0:09:17
0:09:17
Introduction to Big Data Architecture
 0:07:37
0:07:37
A short introduction to Support Vector Machine (SVM)
 0:01:21
0:01:21
Le big data - 60 secondes pour comprendre
 0:28:30
0:28:30
Big Data Analytics | What Is Big Data Analytics? | Big Data Analytics For Beginners | Simplilearn
 0:17:36
0:17:36
Big Data In 17 Minutes | What Is Big Data? | Introduction To Big Data | Trendytech
 0:42:34
0:42:34
Big Data Tutorial For Beginners | What Is Big Data | Big Data Tutorial | Hadoop Training | Edureka
 1:33:19
1:33:19
Introduction to Big Data, Data Science, and Predictive Analytics
 0:01:46
0:01:46
Big Data and Hadoop - Introduction
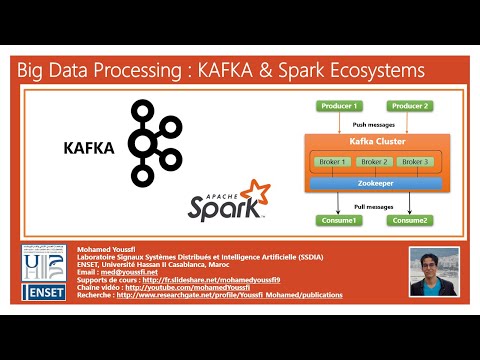 0:58:28
0:58:28
Part 1 - Big Data Processing Introduction au Big Data
 0:15:06
0:15:06
What is Big Data? Introduction to Big Data | Hadoop Tutorial for Beginners | Hadoop [Part 1]
 0:06:58
0:06:58
Big Data Tools and Technologies | Big Data Tools Tutorial | Big Data Training | Simplilearn
 0:31:55
0:31:55
Big Data Tutorial For Beginners - Lesson 1 | Big Data Introduction | Simplilearn
 0:14:22
0:14:22
Using Big Data to Improve Healthcare Services | Tiranee Achalakul | TEDxChiangMai
 0:09:04
0:09:04
What Is Data Analytics? - An Introduction (Full Guide)
 0:09:28
0:09:28
Lec-127: Introduction to Hadoop🐘| What is Hadoop🐘| Hadoop Framework🖥
 1:23:58
1:23:58
Big Data Analytics for Non-Programmers | Introduction to Big Data | Hadoop Tutorial | Edureka
 0:30:05
0:30:05
What Is Hadoop? | Introduction To Hadoop | Hadoop Tutorial For Beginners | Simplilearn
Комментарии