filmov
tv
Unicode decode error utf8 codec can t decode byte

Показать описание
unicodedecodeerror: 'utf-8' codec can't decode byte... - a comprehensive guide
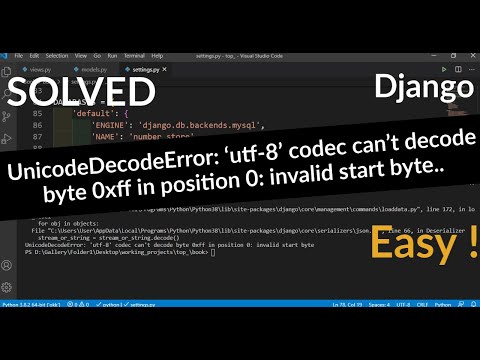
this error, "unicodedecodeerror: 'utf-8' codec can't decode byte 0xxx in position y: invalid continuation byte," is a common headache for programmers working with text, especially when dealing with data from various sources like files, databases, or web apis. it arises when your program tries to interpret a sequence of bytes as a utf-8 encoded string, but the byte sequence isn't actually valid utf-8. let's break down the error, understand its causes, and explore various solutions.
**1. understanding the fundamentals: encoding, decoding, unicode, and utf-8**
before diving into the error, let's establish the basic concepts.
* **characters:** characters are the letters, numbers, punctuation marks, and symbols we use to represent text. think 'a', 'a', '1', '$', '!', '©', '你好'.
* **character sets (or character encodings):** a character set (or code page) is a mapping between characters and numerical values (code points). early character sets, like ascii, used only 7 bits (128 characters) and could only represent english characters. extended ascii used 8 bits (256 characters) and added some symbols and accented characters, but still wasn't enough for many languages.
* **unicode:** unicode is a universal character set that aims to include *every* character used in *every* writing system in the world. it assigns a unique numerical value (code point) to each character. unicode provides the *standard* mapping of characters to code points, but it doesn't specify how these code points are stored in bytes. the unicode standard uses hexadecimal notation to represent code points, denoted with `u+` followed by four to six hexadecimal digits. for example: 'a' is u+0041, '你好' is u+4f60.
* **encodings (unicode transformations):** encodings define how unicode code points are represented as sequences of bytes for storage or transmission. different encodings use different strategies. the ...
#UnicodeDecodeError #UTF8Codec #PythonErrors
unicode decode error
utf8 codec
can't decode byte
character encoding
string decoding
byte to string
encoding error
Python error handling
text encoding issues
invalid byte sequence
UnicodeDecodeError
data corruption
UTF-8 issues
character set
error traceback
this error, "unicodedecodeerror: 'utf-8' codec can't decode byte 0xxx in position y: invalid continuation byte," is a common headache for programmers working with text, especially when dealing with data from various sources like files, databases, or web apis. it arises when your program tries to interpret a sequence of bytes as a utf-8 encoded string, but the byte sequence isn't actually valid utf-8. let's break down the error, understand its causes, and explore various solutions.
**1. understanding the fundamentals: encoding, decoding, unicode, and utf-8**
before diving into the error, let's establish the basic concepts.
* **characters:** characters are the letters, numbers, punctuation marks, and symbols we use to represent text. think 'a', 'a', '1', '$', '!', '©', '你好'.
* **character sets (or character encodings):** a character set (or code page) is a mapping between characters and numerical values (code points). early character sets, like ascii, used only 7 bits (128 characters) and could only represent english characters. extended ascii used 8 bits (256 characters) and added some symbols and accented characters, but still wasn't enough for many languages.
* **unicode:** unicode is a universal character set that aims to include *every* character used in *every* writing system in the world. it assigns a unique numerical value (code point) to each character. unicode provides the *standard* mapping of characters to code points, but it doesn't specify how these code points are stored in bytes. the unicode standard uses hexadecimal notation to represent code points, denoted with `u+` followed by four to six hexadecimal digits. for example: 'a' is u+0041, '你好' is u+4f60.
* **encodings (unicode transformations):** encodings define how unicode code points are represented as sequences of bytes for storage or transmission. different encodings use different strategies. the ...
#UnicodeDecodeError #UTF8Codec #PythonErrors
unicode decode error
utf8 codec
can't decode byte
character encoding
string decoding
byte to string
encoding error
Python error handling
text encoding issues
invalid byte sequence
UnicodeDecodeError
data corruption
UTF-8 issues
character set
error traceback
 0:01:51
0:01:51
 0:02:58
0:02:58
 0:16:21
0:16:21
 0:00:58
0:00:58
 0:03:47
0:03:47
 0:01:32
0:01:32
 0:01:43
0:01:43
 0:00:58
0:00:58
 0:02:04
0:02:04
 0:00:29
0:00:29
 0:01:03
0:01:03
 0:03:11
0:03:11
 0:02:41
0:02:41
 0:02:25
0:02:25
 0:01:24
0:01:24
 0:03:21
0:03:21
 0:00:59
0:00:59
 0:02:31
0:02:31
 0:01:29
0:01:29
 0:02:21
0:02:21
 0:02:56
0:02:56
 0:01:21
0:01:21
 0:01:43
0:01:43
 0:01:26
0:01:26