filmov
tv
GTC 2022 - How CUDA Programming Works - Stephen Jones, CUDA Architect, NVIDIA
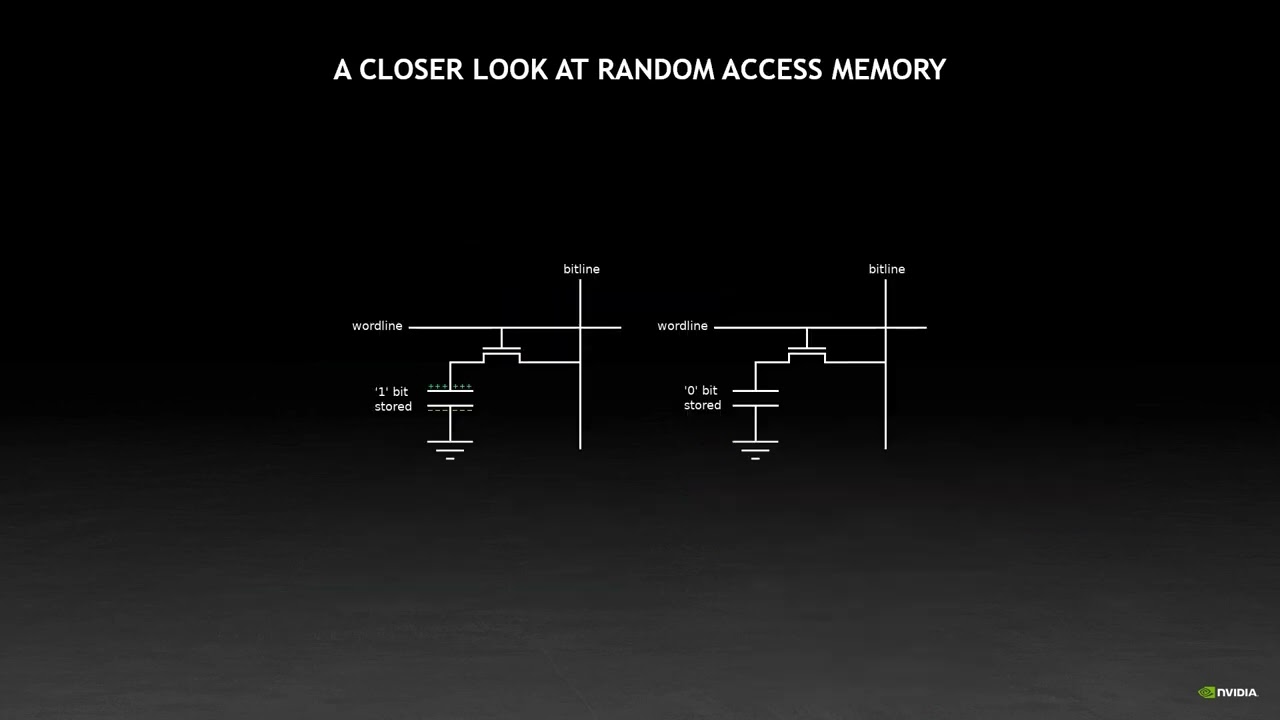
Показать описание
Come for an introduction to programming the GPU by the lead architect of CUDA. CUDA's unique in being a programming language designed and built hand-in-hand with the hardware that it runs on. Stepping up from last year's "How GPU Computing Works" deep dive into the architecture of the GPU, we'll look at how hardware design motivates the CUDA language and how the CUDA language motivates the hardware design. This is not a course on CUDA programming. It's a foundation on what works, what doesn't work, and why. We'll tell you how to think about a problem in a way that will run well on the GPU, and you'll see how the CUDA programming model is built to run that way. If you're new to CUDA, we'll give you the core background knowledge you need — getting started begins with understanding. If you're an expert, hopefully you'll face your next optimization problem with a new perspective on what might work, and why.
 0:41:14
0:41:14
How CUDA Programming Works | GTC 2022
 0:41:15
0:41:15
GTC 2022 - How CUDA Programming Works - Stephen Jones, CUDA Architect, NVIDIA
 0:47:34
0:47:34
GTC 2022 - CUDA: New Features and Beyond - Stephen Jones, CUDA Architect, NVIDIA
 0:53:44
0:53:44
CUDA New Features and Beyond | GTC 2022
 0:50:08
0:50:08
CUDA: New Features and Beyond | NVIDIA GTC 2024
 0:17:54
0:17:54
How Nvidia Grew From Gaming To A.I. Giant, Now Powering ChatGPT
 0:38:06
0:38:06
HOW CUDA PROGRAMMING WORKS . GTC2022
 1:40:55
1:40:55
GTC 2022 Spring Keynote with NVIDIA CEO Jensen Huang
 0:39:36
0:39:36
How GPU Computing Works | GTC 2021
 2:03:05
2:03:05
GTC March 2024 Keynote with NVIDIA CEO Jensen Huang
 0:00:19
0:00:19
CVCUDA/CV-CUDA - Gource visualisation
 0:01:19
0:01:19
Runway Optimizing AI Image and Video Generation Tools Using CV-CUDA
 1:00:00
1:00:00
CUDA 12 New Features and Beyond
 0:15:32
0:15:32
Writing Code That Runs FAST on a GPU
 0:05:03
0:05:03
GTC 2022 Keynote Highlights & Update
 2:00:08
2:00:08
Nvidia CEO Jensen Huang full keynote at GTC 2024
 0:09:07
0:09:07
CUDA Tutorials I CUDA Compatibility
 0:03:35
0:03:35
Final Plans for NVIDIA GTC 2022
 0:19:37
0:19:37
Nvidia CUDA Explained – C/C++ Syntax Analysis and Concepts
 0:01:58
0:01:58
OpenAI's ChatGPT CUDA Lessons - 001 Hello World - Learn CUDA C++ Here | Kinvert
 0:39:04
0:39:04
Parallel Computing with Nvidia CUDA
 0:56:20
0:56:20
Cuda Graphs
 1:37:42
1:37:42
GTC Sept 2022 Keynote with NVIDIA CEO Jensen Huang
 0:58:38
0:58:38
AI and The Next Computing Platforms With Jensen Huang and Mark Zuckerberg
Комментарии