filmov
tv
WGANs: A stable alternative to traditional GANs || Wasserstein GAN

Показать описание
In this video, we'll explore the Wasserstein GAN with Gradient Penalty, which addresses the instability issues in traditional GANs. Unlike traditional GANs, WGANs use the Wasserstein distance as their loss function to measure the difference between the real and generated data distributions. The Gradient penalty is used to ensure that the gradients from the discriminator don't explode or vanish. We'll implement the WGAN with Gradient Penalty from scratch and use the anime faces dataset for training. Watch the video to learn how to create this type of GAN and improve its performance.
And as always,
Thanks for watching ❤️
Chapters:
0:00 Intro
0:34 Wasserstein distance
1:15 Wasserstein as loss function
2:43 Gradient Penalty (Lipschitz continuity)
4:38 Code from scratch
11:45 Things to remember
And as always,
Thanks for watching ❤️
Chapters:
0:00 Intro
0:34 Wasserstein distance
1:15 Wasserstein as loss function
2:43 Gradient Penalty (Lipschitz continuity)
4:38 Code from scratch
11:45 Things to remember
 0:12:38
0:12:38
WGANs: A stable alternative to traditional GANs || Wasserstein GAN
 0:08:59
0:08:59
Wasserstein Generative adversarial Networks (WGANs) in Tensorflow
 0:13:32
0:13:32
Nuts and Bolts of WGANs, Kantorovich-Rubistein Duality, Earth Movers Distance
 0:10:13
0:10:13
Gradient Penalty | Lecture 68 (Part 3) | Applied Deep Learning
 0:28:01
0:28:01
SGD Learns One-Layer Networks in WGANs
 0:07:19
0:07:19
Wasserstein GAN | Lecture 67 (Part 4) | Applied Deep Learning
 0:25:59
0:25:59
WGAN implementation from scratch (with gradient penalty)
 0:05:44
0:05:44
DC-GAN Explained!
 0:15:04
0:15:04
Wasserstein GAN (Continued) | Lecture 68 (Part 1) | Applied Deep Learning
 0:01:01
0:01:01
Alias-Free GAN: bag edition
 0:12:33
0:12:33
WGAN with Gradient Penalty and Attention- theory, implementation and results!
 0:27:31
0:27:31
CS 182: Lecture 19: Part 3: GANs
 0:04:44
0:04:44
A simpler self attention GAN v1
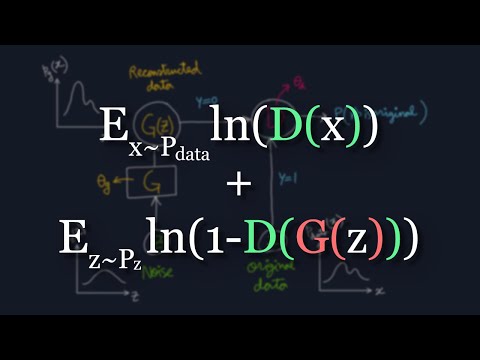 0:17:04
0:17:04
The Math Behind Generative Adversarial Networks Clearly Explained!
 0:03:46
0:03:46
Major Generative Adversarial Networks (GAN) Variants
 0:20:19
0:20:19
Anomaly Detection with Generative Adversarial Networks (GANs) Leveraging Failure Simulation Data
 0:09:38
0:09:38
Generative Adversarial Networks, but it's actually fun (with fastai)
 0:39:55
0:39:55
Training Wasserstein Generative Adversarial Networks Without Gradient Penalties
 0:12:51
0:12:51
What are Generative Adversarial Networks (GANs)? - Introduction to Deep Learning
 0:08:12
0:08:12
Generative Adversarial Networks (GANs) Explained: How They Work, Types, and Applications
 0:06:18
0:06:18
A Style-Based Generator Architecture for Generative Adversarial Networks
 0:28:19
0:28:19
How To Train Your WGAN-GP To Generate Fake People Portraits
 0:03:20
0:03:20
Wasserstein Distance Explained | Data Science Fundamentals
 0:11:17
0:11:17
A History of GANs
Комментарии