filmov
tv
Lecture 19: Generative Models I

Показать описание
Lecture 19 is the first of two lectures about generative models. We compare supervised and unsupervised learning, and also compare discriminative vs generative models. We discuss autoregressive generative models that explicitly model densities, including PixelRNN and PixelCNN. We discuss autoencoders as a method for unsupervised feature learning, and generalize them to variational autoencoders which are a type of generative model that use variational inference to maximize a lower-bound on the data likelihood.
_________________________________________________________________________________________________
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image classification and object detection. Recent developments in neural network approaches have greatly advanced the performance of these state-of-the-art visual recognition systems. This course is a deep dive into details of neural-network based deep learning methods for computer vision. During this course, students will learn to implement, train and debug their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. We will cover learning algorithms, neural network architectures, and practical engineering tricks for training and fine-tuning networks for visual recognition tasks.
_________________________________________________________________________________________________
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image classification and object detection. Recent developments in neural network approaches have greatly advanced the performance of these state-of-the-art visual recognition systems. This course is a deep dive into details of neural-network based deep learning methods for computer vision. During this course, students will learn to implement, train and debug their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. We will cover learning algorithms, neural network architectures, and practical engineering tricks for training and fine-tuning networks for visual recognition tasks.
 1:11:13
1:11:13
Lecture 19: Generative Models I
 1:18:47
1:18:47
Lecture 19-1. Generative Models I
 0:25:54
0:25:54
Lecture 19-2. Generative Models I
 1:37:47
1:37:47
Lecture 19 - Efficient Video Understanding and Generative Models | MIT 6.S965
 1:37:41
1:37:41
Lecture 19 - Efficient Video Understanding and Generative Models | MIT 6.S965
 1:14:41
1:14:41
Lecture 19: Generative Models Part 1 (UMich EECS 498-007)
 0:54:58
0:54:58
Computational Creativity Lecture 19: Generative Models for Music
 1:19:37
1:19:37
Lecture 19-1. Generative Models II
 0:56:19
0:56:19
MIT 6.S191 (2024): Deep Generative Modeling
 0:50:23
0:50:23
Lecture 20-1. Generative Models II
 1:09:36
1:09:36
Lecture 7.2: Generative Models (Multimodal Machine Learning, Carnegie Mellon University)
 0:22:46
0:22:46
CS 182: Lecture 19: Part 1: GANs
 0:57:28
0:57:28
Stanford CS236: Deep Generative Models I 2023 I Lecture 1 - Introduction
 1:17:38
1:17:38
Lecture 18-2. Generative Models I
![[Lecture 19] 11785](https://i.ytimg.com/vi/CoSzKWkGmVA/hqdefault.jpg) 1:21:00
1:21:00
[Lecture 19] 11785 Intro to Deep Learning - Fall 2018
 0:12:58
0:12:58
Machine Learning: Lecture 24b: Discriminative and Generative models
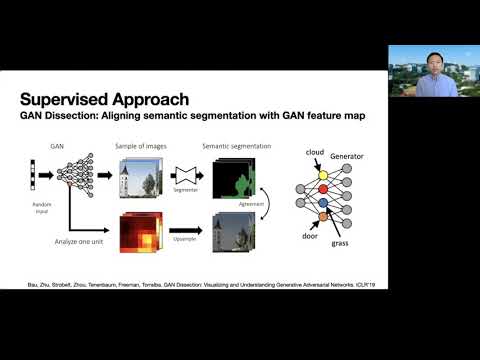 0:44:26
0:44:26
Interpreting Deep Generative Models for Interactive AI Content Creation by Bolei Zhou (CUHK)
 1:02:54
1:02:54
AI Course 2021 - week 9 - Generative models
 0:43:44
0:43:44
MIT 6.S191 (2019): Deep Generative Modeling
 0:15:05
0:15:05
Lecture 19-2. Generative Models II
 1:07:26
1:07:26
Generative Models for Image Synthesis
 1:17:30
1:17:30
Lecture 19 RL as Inference 1
 1:31:08
1:31:08
Deep Generative Models by Thomas Lucas
 2:37:19
2:37:19
Giovanni Conforti, Alain Durmus - An introduction to Score-based Generative Models - Lecture 1
Комментарии