filmov
tv
Mastering GCP Read, Embed, and Search Data in BigQuery Vector Database Context Summarization by LLM

Показать описание
Learn how to seamlessly integrate various Google Cloud Platform (GCP) services for advanced data processing and retrieval. In this tutorial, we walk through the steps to:
Read files from a GCP bucket.
Perform document embedding.
Push documents to Google Big Query Vector Database.
Conduct a similarity search using custom metadata filters.
Send the RAG (Retrieval-Augmented Generation) search results to ChatVertexAI for summarization.
Whether you're a data scientist, developer, or cloud enthusiast, this video provides a comprehensive guide to leveraging GCP's powerful tools for efficient and accurate information retrieval and summarization with LLM.
Read files from a GCP bucket.
Perform document embedding.
Push documents to Google Big Query Vector Database.
Conduct a similarity search using custom metadata filters.
Send the RAG (Retrieval-Augmented Generation) search results to ChatVertexAI for summarization.
Whether you're a data scientist, developer, or cloud enthusiast, this video provides a comprehensive guide to leveraging GCP's powerful tools for efficient and accurate information retrieval and summarization with LLM.
 0:50:54
0:50:54
Mastering GCP Read, Embed, and Search Data in BigQuery Vector Database Context Summarization by LLM
 0:34:04
0:34:04
Mastering GCP Read, Embed, and Search Data in BigQuery Vector Database Part1
 0:06:17
0:06:17
Industrial-scale Web Scraping with AI & Proxy Networks
 0:02:31
0:02:31
RabbitMQ in 100 Seconds
 0:00:15
0:00:15
My Jobs Before I was a Project Manager
 0:07:01
0:07:01
Use Google BigQuery & Gemini AI For Data Analytics
 0:13:28
0:13:28
Mastering Google Docs Automation with Node.js: Read & Write like a Pro!
 0:04:18
0:04:18
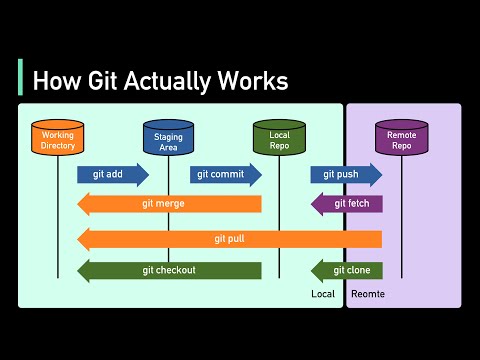
How Git Works: Explained in 4 Minutes
 0:04:21
0:04:21
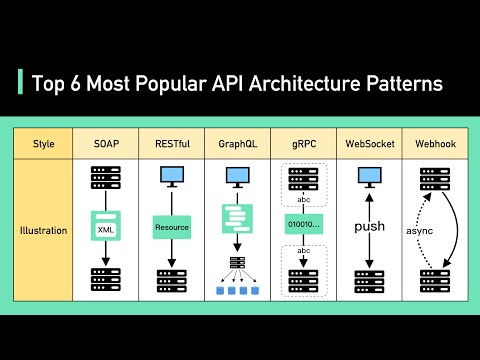
Top 6 Most Popular API Architecture Styles
 0:08:19
0:08:19
How to Crack Any System Design Interview
 0:00:34
0:00:34
Ashneer views on Ai & jobs (shocking😱)
 0:18:35
0:18:35
Building Production-Ready RAG Applications: Jerry Liu
 0:14:19
0:14:19
Integrating Generative AI Models with Amazon Bedrock
 0:42:04
0:42:04
Harden Your VMs with Shielded Computing (Cloud Next '19)
 0:16:24
0:16:24
How to enable Google CDN for custom origin websites | Google CDN for external websites
 0:41:24
0:41:24
justforfunc #19: mastering io.Pipes
 1:06:58
1:06:58
Generate, Store, and Index Vector Embeddings with Google Cloud and MongoDB Atlas
 0:43:55
0:43:55
Powerful Analytics With Dataiku and GCP
 0:07:50
0:07:50
How to Play a m3u8 File with HTML5 Video Element
 0:08:11
0:08:11
Isomap Embedding and LLE Dimensionality Reduction Techniques
 0:05:48
0:05:48
Debugging Like A Pro
 2:33:42
2:33:42
Basics of GCP | Google Cloud Platform Basics | Cloud Computing Tutorial | Simplilearn
 2:06:48
2:06:48
DAY-10 | Mastering ChromaDB Vector Databases
 0:16:20
0:16:20
Node.js Ultimate Beginner’s Guide in 7 Easy Steps
Комментарии