filmov
tv
Single Shot Detector | SSD | Object Detection Using SSD

Показать описание
Explained what is Single Shot Detector.
You can learn other object detection algorithms from below given link:
If you have any questions with what we covered in this video then feel free to ask in the comment section below & I'll do my best to answer your queries.
Please consider clicking the SUBSCRIBE button to be notified for future videos & thank you all for watching.
Support my channel 🙏 by LIKE ,SHARE & SUBSCRIBE
Support my channel 🙏 by LIKE ,SHARE & SUBSCRIBE
Single Shot Detector(SSD) – Real Time Object Detection
Object Detection Is A Technique In Computer Vision That Deals With Detecting Examples Of Semantic Targets Of A Specific Class (Eg. Cars, Buildings Or Humans) In Images And Videos. It Is A Technique That Works To Locate And Identify Objects In Digital Images And Videos.
It Specifically Draws Bounding Boxes Around The Object Which Help Us To Locate Where The Objects Are. Many A Times Object Detection Is Mix With Image Recognition.
SSD
There Are Many Object Detection Algorithms In Practice Like R-CNN, Fast R-CNN, Faster R-CNN Etc..
But Single Shot Algorithms More Efficient And Have A Good Accuracy. They Use Deep Learning Based Approaches For Object Detection.
How Single Shot Detection(SSD) Is Different:-
Single Shot Detection – This Means That The Tasks Of Object Localization And Object Classification Are Ready In A Single Forward Pass Of The Network.
Detector – The Network Is A Detector That Also Classifies The Detected Objects.
Single Shot Detector Is Faster Than The Previous State-Of-The-Art Techniques(YOLO) And Is Significantly More Accurate.
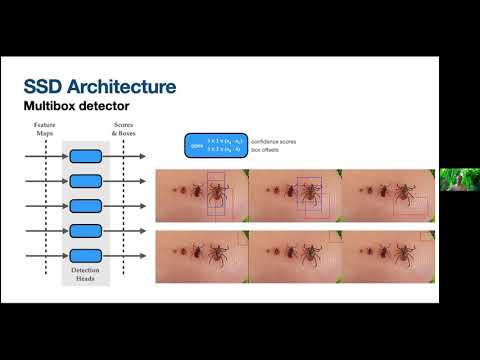
SSD Predicts Category Scores And Box Offsets For A Fixed Number Of Default Bounding Boxes Using Convolution Filters Applied To Feature Maps.
To Achieve High Accuracy We Produce Predictions Of Different Scales From Feature Maps Of Different Dimensions, And Then Separate The Predictions By Aspect Ratio.
These Features Lead To High Accuracy, Even On Low Resolution Input Images.
Other Algorithms Normally Use Object Proposal Methodology Where They Would Come Up With A Way To Break Down The Image Segmented Into Parts To Suggest Where They Could Potentially Be Objects. These Algorithms Sacrifice Accuracy.
Therefore Researchers Came Up With An Interesting Solution Where They Do Everything In One Single Shot. It Just Looks At The Image Once, It Doesn’t Have To Go Back To The Image Again, It Doesn’t Have To Run Many Convolutional Neural Networks.
#SingleShotDetector #SSD #ObjectDetection #PifordTechnologies #AI #ArtificialIntelligence #DeepLearning #ConvolutionalNeuralNetwork #CNN #ComputerVision
You can learn other object detection algorithms from below given link:
If you have any questions with what we covered in this video then feel free to ask in the comment section below & I'll do my best to answer your queries.
Please consider clicking the SUBSCRIBE button to be notified for future videos & thank you all for watching.
Support my channel 🙏 by LIKE ,SHARE & SUBSCRIBE
Support my channel 🙏 by LIKE ,SHARE & SUBSCRIBE
Single Shot Detector(SSD) – Real Time Object Detection
Object Detection Is A Technique In Computer Vision That Deals With Detecting Examples Of Semantic Targets Of A Specific Class (Eg. Cars, Buildings Or Humans) In Images And Videos. It Is A Technique That Works To Locate And Identify Objects In Digital Images And Videos.
It Specifically Draws Bounding Boxes Around The Object Which Help Us To Locate Where The Objects Are. Many A Times Object Detection Is Mix With Image Recognition.
SSD
There Are Many Object Detection Algorithms In Practice Like R-CNN, Fast R-CNN, Faster R-CNN Etc..
But Single Shot Algorithms More Efficient And Have A Good Accuracy. They Use Deep Learning Based Approaches For Object Detection.
How Single Shot Detection(SSD) Is Different:-
Single Shot Detection – This Means That The Tasks Of Object Localization And Object Classification Are Ready In A Single Forward Pass Of The Network.
Detector – The Network Is A Detector That Also Classifies The Detected Objects.
Single Shot Detector Is Faster Than The Previous State-Of-The-Art Techniques(YOLO) And Is Significantly More Accurate.
SSD Predicts Category Scores And Box Offsets For A Fixed Number Of Default Bounding Boxes Using Convolution Filters Applied To Feature Maps.
To Achieve High Accuracy We Produce Predictions Of Different Scales From Feature Maps Of Different Dimensions, And Then Separate The Predictions By Aspect Ratio.
These Features Lead To High Accuracy, Even On Low Resolution Input Images.
Other Algorithms Normally Use Object Proposal Methodology Where They Would Come Up With A Way To Break Down The Image Segmented Into Parts To Suggest Where They Could Potentially Be Objects. These Algorithms Sacrifice Accuracy.
Therefore Researchers Came Up With An Interesting Solution Where They Do Everything In One Single Shot. It Just Looks At The Image Once, It Doesn’t Have To Go Back To The Image Again, It Doesn’t Have To Run Many Convolutional Neural Networks.
#SingleShotDetector #SSD #ObjectDetection #PifordTechnologies #AI #ArtificialIntelligence #DeepLearning #ConvolutionalNeuralNetwork #CNN #ComputerVision
 0:09:00
0:09:00
Single Shot Detector | SSD | Object Detection Using SSD
 0:31:44
0:31:44
MLT __init__ Session #4 – SSD: Single Shot MultiBox Detector
 0:03:23
0:03:23
SSD: Single Shot MultiBox Detector
 0:01:07
0:01:07
Single Shot Multibox Detector (SSD) Demo
 0:56:01
0:56:01
Single Shot Multibox Detector | SSD Object Detection Explained and Implemented
 0:08:20
0:08:20
Object Detection Using Single Shot Multibox Detector
 0:19:51
0:19:51
SSD | Lecture 39 (Part 1) | Applied Deep Learning
 0:03:37
0:03:37
Deep Learning - 031 Single shot detectors
 0:00:19
0:00:19
Object Detection using SSD(Single Shot Multibox detector)
 0:05:14
0:05:14
WACV18: Context-Aware Single-Shot Detector
 0:05:07
0:05:07
Object Detection best model / best algorithm in 2023 | YOLO vs SSD vs Faster-RCNN comparison Python
 0:14:39
0:14:39
SSD: Single Shot MultiBox Detector (How it works)
 0:36:01
0:36:01
PR-132: SSD: Single Shot MultiBox Detector
 0:08:35
0:08:35
L16/5 SSD and YOLO
 0:10:48
0:10:48
Single Shot Detector SSD | Deep Learning Object Dectection Model| Computer Vision
 0:00:09
0:00:09
Drone Aerial Single Shot Detector (SSD) - Deep Learning Experiment
 0:03:13
0:03:13
TensorFlow Object Detection API with Single Shot MultiBox Detector (SSD)
 0:12:09
0:12:09
SSD: Single Shot MultiBox Detector
 0:16:47
0:16:47
Object Detection using PyTorch for image using SSD | Single Shot Detection in Google Colab - Python
 0:26:32
0:26:32
Single Shot Detector On Custom Dataset | SSD | Object Detection Using SSD
 0:00:50
0:00:50
Single shot multibox detector SSD, Object detection
 0:42:43
0:42:43
4K SSD Object Detection #1
 0:00:30
0:00:30
Snowy Driving Single Shot Detector (SSD) - Deep Learning Experiment
 0:00:35
0:00:35
single-shot detector (SSD) on Road Sign
Комментарии