filmov
tv
Vision Transformer for Image Classification
Показать описание
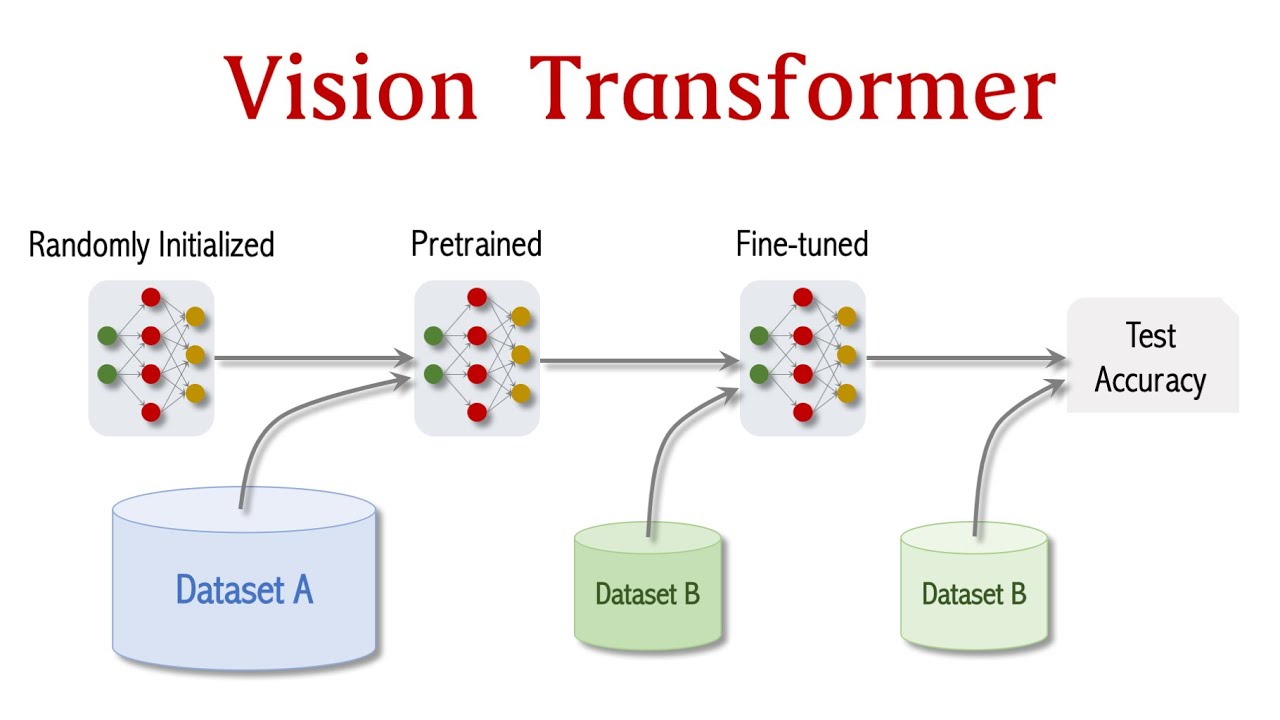
Vision Transformer (ViT) is the new state-of-the-art for image classification. ViT was posted on arXiv in Oct 2020 and officially published in 2021. On all the public datasets, ViT beats the best ResNet by a small margin, provided that ViT has been pretrained on a sufficiently large dataset. The bigger the dataset, the greater the advantage of the ViT over ResNet.
Reference:
- Dosovitskiy et al. An image is worth 16×16 words: transformers for image recognition at scale. In ICLR, 2021.
Reference:
- Dosovitskiy et al. An image is worth 16×16 words: transformers for image recognition at scale. In ICLR, 2021.
 0:14:47
0:14:47
Vision Transformer for Image Classification
 0:16:51
0:16:51
Vision Transformer Quick Guide - Theory and Code in (almost) 15 min
 0:29:56
0:29:56
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained)
 0:34:13
0:34:13
Image Classification Using Vision Transformer | ViTs
 0:13:44
0:13:44
Vision Transformers explained
 0:10:41
0:10:41
Vision Transformer for Image Classification Using transfer learning
 0:30:27
0:30:27
Vision Transformers (ViT) Explained + Fine-tuning in Python
 0:05:26
0:05:26
An image is worth 16x16 words: ViT | Vision Transformer explained
 0:06:30
0:06:30
Machine Learning Interview Questions Session 1
 0:07:37
0:07:37
Vision Transformer (ViT) - Using Transformers for Image Classification | HuggingFace
 0:21:54
0:21:54
Vision Transformer - Keras Code Examples!!
 0:21:04
0:21:04
New TECH: Vision Transformer 2023 on Image Classification | AI
 1:14:35
1:14:35
Image Classification using Vision Transformer (ViT) in TensorFlow
 0:18:56
0:18:56
Vision Transformer Explained
 0:30:49
0:30:49
Vision Transformer Basics
 0:13:21
0:13:21
Image Classification Computer Vision with Hugging Face Transformers -Google ViT - Python ML Tutorial
 0:34:38
0:34:38
Vision Transformer and its Applications
 0:09:37
0:09:37
Vision Transformer Attention
 0:27:21
0:27:21
Are Transformers better than CNN's at Image Classification? An end to end project #cnn #transfo...
 0:32:02
0:32:02
ResNet50 ViT - Vision Transformer with ResNet50 Implementation in TensorFlow
 0:24:57
0:24:57
Vision Transformer (ViT) - An image is worth 16x16 words | Paper Explained
 0:00:30
0:00:30
Vision transformers: query and key images
 0:10:54
0:10:54
Hugging Face - Walkthrough, Discussions, Demo with Vision Transformer for Image Classification
 0:32:51
0:32:51
Vision Transformer (ViT) Paper Explanation
Комментарии