filmov
tv
How to Bypass 403 Forbidden Error When Web Scraping: Tutorial

Показать описание
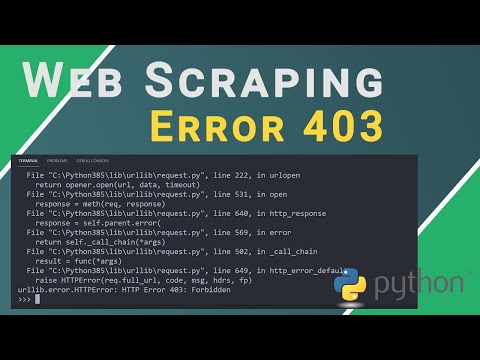
The 403 Forbidden Error is an HTTP response status code that declines permission to the target website. When web scraping, it can mean that the website detected bot activity and blocked access to the server. Solving this issue might require three steps based on the detection level the target website implements.
Following this guide, you’ll learn about user agents, request headers, and proxy rotation. We’ll show you a method of adjusting and rotating user agents, as well as optimizing request headers for complexity and consistency. In addition, you’ll learn about our unblocking solution that guarantees you’ll never get the 403 error again.
📚 *VIDEO RESOURCES*
HTTP headers supported by popular browsers:
Learn to Rotate Proxies in Python:
🔧 *OUR SCRAPING SOLUTIONS*
Residential Proxies:
Shared Datacenter Proxies:
Dedicated Datacenter Proxies
SOCKS5 Proxies:
🤝 *LET'S CONNECT*
⏳ *TIMESTAMPS*
0:00 Bypassing the 403 Forbidden Error Tutorial
0:20 403 Forbidden Error Explained
0:52 What could solve this error?
1:15 What is a User Agent?
1:51 Adjusting and Rotating User Agents
4:54 Complexity of Request Headers
7:23 Consistency of Request Headers
7:55 Setting Up Request Headers
9:13 Using and Rotating Proxies
10:11 Easier Solution to the 403 Forbidden Error
11:15 Ending
🎥 *RELATED VIDEOS*
Step-by-Step Web Scraping Tutorial With Python:
How to Scrape Difficult Targets Without Getting Blocked:
How to Rotate Proxies With Python (Easy & Quick Tutorial):
© 2023 Oxylabs. All rights reserved.
#Oxylabs #403forbidden #scraping
 0:02:30
0:02:30
Bypassing 403 Forbidden Errors with Burp Suite & Extension | 403 bypasser
 0:07:01
0:07:01
Filters Bypass Web App directory/file | Bug Bounty | Ethical Hacking
 0:11:35
0:11:35
How to Bypass 403 Forbidden Error When Web Scraping: Tutorial
 0:06:45
0:06:45
Bypass 403 Forbidden Error When Web Scraping in Python
 0:10:53
0:10:53
BUG BOUNTY: UNDERSTANDING 403 BYPASS IN DEPTH | LIVE DEMONSTRATION | 2024
 0:06:02
0:06:02
Bypass 403 Errors : A Beginner's Guide #cybersecurity #ethicalhacking #bugbounty
 0:10:56
0:10:56
BUG BOUNTY TUTORIAL: BYPASSING 403 #1
 0:12:20
0:12:20
BUG HUNTING: 403 forbidden bypass #2 | Bug Bounty Tutorial | 2022
 0:02:08
0:02:08
How To Fix ''Fail to login''/''Error Connecting'' in GROWTOP...
 0:12:32
0:12:32
Bug Bounty: How Developers Implement 403 & How To Bypass Them? | 2024
 0:03:10
0:03:10
How To Bypass 403 Forbidden #bugbounty #cybersecurity #poc #0xd3vil #bypass403 #pocvideo #bugpoc
 0:00:36
0:00:36
roblox bypass error 403 in a minute
 0:00:29
0:00:29
How To Fix Roblox Error Code 403 - Authentication Failed
 0:02:57
0:02:57
Scrape Websites with 403 Errors and bypass cloudflare
 0:02:05
0:02:05
403 Forbidden Bypass | POC
 0:04:37
0:04:37
How To Bypass Admin Panel || 403 Bypass || Manual And Automation Method||
 0:02:41
0:02:41
Burp Extension Mini series | 403 Bypasser | Bug Bounty Service LLC
 0:04:03
0:04:03
Bug Bounty Tutorial : 403 forbidden bypass
 0:18:32
0:18:32
Bug Bounty Tips: HTTP code 403 forbidden bypass
 0:01:13
0:01:13
403 Forbidden Error Fix Windows 10 / 8 | How to fix Website Error Code 403 Access Denied on Chrome
 0:02:41
0:02:41
Fix 403 Forbidden Error on Google Chrome Windows 11 / 10/8/7 | How To Solve forbidden 403 error 🌐✅...
 0:04:48
0:04:48
How To BYPASS 403 Forbidden | Dirdar Tool | Bounty Tools
 0:08:04
0:08:04
Forbidden-Buster Bypass HTTP 401 & 403 Response
 0:03:48
0:03:48
SQL injection challengs solution forbidden waf 403 bypass and print dios manually
Комментарии