filmov
tv
Understanding Spark SQL: Optimizing View Queries with Partition Columns

Показать описание
Discover how to effectively utilize partition columns in `Spark SQL` views to optimize query performance and ensure efficient data processing.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Spark SQL view and partition column usage
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding Spark SQL: Optimizing View Queries with Partition Columns
Using Apache Spark SQL efficiently can greatly enhance your data processing performance, especially when dealing with large datasets. If you're querying a table with a partition column directly, you might notice a significant speed difference compared to querying through a view that utilizes window functions. In this guide, we'll discuss a common issue encountered when using partition columns in views and explore ways to optimize performance.
The Problem: Slow Queries through Views
Consider the following scenario:
You have a large Databricks table named TableA, consisting of approximately 3000 columns, with a partition column called dldate. When querying this table directly with the command:
[[See Video to Reveal this Text or Code Snippet]]
the query completes in seconds. However, if you create a view view_tableA that includes some window functions and run the command:
[[See Video to Reveal this Text or Code Snippet]]
you may find that the query runs indefinitely. This leads to a crucial question – Will the latter query effectively use the partition key of the table? If not, how can we ensure that the partition key is used for optimization?
The Solution: Ensuring Partition Key Usage in Views
To optimize your queries when working with views, here are some strategies to ensure that the partition key is utilized effectively:
1. Align Window Functions with Partitioning
When using window functions in your queries, it’s essential that the partitioning aligns with the table’s partitioning to allow the query optimizer to perform partition pruning.
Example of Correct Alignment:
[[See Video to Reveal this Text or Code Snippet]]
This structure allows the optimizer to push down the predicate, applying partition pruning and fetching data efficiently from the relevant partition.
2. Avoid Inappropriate Partitioning
Compare the previous example to a less effective approach:
Incorrect Alignment:
[[See Video to Reveal this Text or Code Snippet]]
In this case, the window function does not use the dldate partition, leading to a slower execution. Without partitioning aligned with the predicate, the optimizer cannot prune partitions, and this results in scanning the entire dataset.
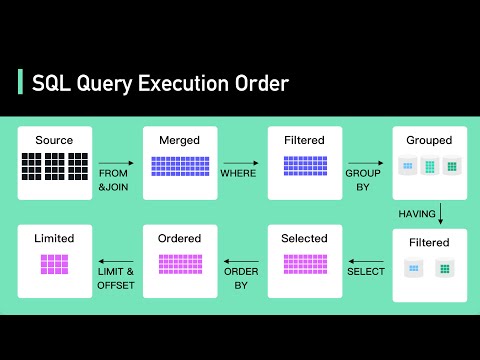
3. Analyze Execution Plans
Utilize the Spark SQL execution plan to understand how your queries are being executed:
Look for elements such as PartitionFilters in the physical plan.
An effective query plan will show PartitionFilters: [isnotnull(dldate), (dldate = '2022-01-01')], indicating that partition pruning is implemented.
Conclusion
Optimizing the use of partition columns in your Spark SQL views is crucial for maintaining efficiency in your data processing tasks. By ensuring that the partitioning of window functions aligns with your table's structure, you can improve query performance significantly. Always analyze execution plans and strive to structure your queries to take full advantage of partitioning.
Implement these strategies when working with views in Spark SQL to enhance the performance of your data queries, making data processing both faster and more efficient.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Spark SQL view and partition column usage
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding Spark SQL: Optimizing View Queries with Partition Columns
Using Apache Spark SQL efficiently can greatly enhance your data processing performance, especially when dealing with large datasets. If you're querying a table with a partition column directly, you might notice a significant speed difference compared to querying through a view that utilizes window functions. In this guide, we'll discuss a common issue encountered when using partition columns in views and explore ways to optimize performance.
The Problem: Slow Queries through Views
Consider the following scenario:
You have a large Databricks table named TableA, consisting of approximately 3000 columns, with a partition column called dldate. When querying this table directly with the command:
[[See Video to Reveal this Text or Code Snippet]]
the query completes in seconds. However, if you create a view view_tableA that includes some window functions and run the command:
[[See Video to Reveal this Text or Code Snippet]]
you may find that the query runs indefinitely. This leads to a crucial question – Will the latter query effectively use the partition key of the table? If not, how can we ensure that the partition key is used for optimization?
The Solution: Ensuring Partition Key Usage in Views
To optimize your queries when working with views, here are some strategies to ensure that the partition key is utilized effectively:
1. Align Window Functions with Partitioning
When using window functions in your queries, it’s essential that the partitioning aligns with the table’s partitioning to allow the query optimizer to perform partition pruning.
Example of Correct Alignment:
[[See Video to Reveal this Text or Code Snippet]]
This structure allows the optimizer to push down the predicate, applying partition pruning and fetching data efficiently from the relevant partition.
2. Avoid Inappropriate Partitioning
Compare the previous example to a less effective approach:
Incorrect Alignment:
[[See Video to Reveal this Text or Code Snippet]]
In this case, the window function does not use the dldate partition, leading to a slower execution. Without partitioning aligned with the predicate, the optimizer cannot prune partitions, and this results in scanning the entire dataset.
3. Analyze Execution Plans
Utilize the Spark SQL execution plan to understand how your queries are being executed:
Look for elements such as PartitionFilters in the physical plan.
An effective query plan will show PartitionFilters: [isnotnull(dldate), (dldate = '2022-01-01')], indicating that partition pruning is implemented.
Conclusion
Optimizing the use of partition columns in your Spark SQL views is crucial for maintaining efficiency in your data processing tasks. By ensuring that the partitioning of window functions aligns with your table's structure, you can improve query performance significantly. Always analyze execution plans and strive to structure your queries to take full advantage of partitioning.
Implement these strategies when working with views in Spark SQL to enhance the performance of your data queries, making data processing both faster and more efficient.
 0:01:35
0:01:35
 1:06:43
1:06:43
 0:05:57
0:05:57
 0:03:00
0:03:00
 0:57:06
0:57:06
 0:31:19
0:31:19
 0:14:27
0:14:27
 0:19:04
0:19:04
 0:40:58
0:40:58
 0:27:14
0:27:14
 0:00:58
0:00:58
 0:11:26
0:11:26
 0:00:50
0:00:50
 0:03:18
0:03:18
 0:39:19
0:39:19
 0:16:40
0:16:40
 0:00:47
0:00:47
 0:03:41
0:03:41
 0:10:47
0:10:47
 0:30:19
0:30:19
 0:00:48
0:00:48
 0:21:34
0:21:34
 0:09:47
0:09:47
 0:01:00
0:01:00