filmov
tv
Using Deep Learning to Extract Feature Data from Imagery

Показать описание
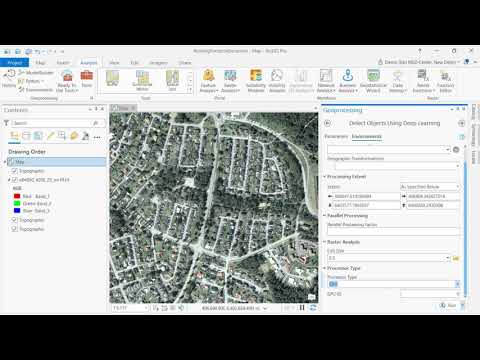
Vector data collection is the most tedious task in a GIS workflow. Digitizing features from imagery or scanned maps is a manual process that is costly, requiring significant human resources to accomplish. Building footprint extraction from imagery provides an even more complex challenge due to shadows, tree overhang, and the complexity of roofs. Often times, this feature extraction work is performed by GIS analysts whose time would be better spent performing analysis and producing actionable reports for decision makers, rather than collecting data. Object detection is a particularly challenging task in computer vision. Today’s advanced deep neural networks (DNN) use algorithms, big data, and the computational power of the GPU to change this dynamic. Machines are now able to learn at a speed, accuracy, and scale that are driving true artificial intelligence and Artificial Intelligence Computing. We will discuss how human-level accuracy can be achieved in vector data collection from commercial imagery at a far greater speed. A good object detection system has to be robust to the presence (or absence) of objects in arbitrary scenes, be invariant to object scale, viewpoint, and orientation, and be able to detect partially occluded objects. Real-world images can contain a few instances of objects or a very large number, this can have an effect on the accuracy and computational efficiency of an object detection system. Historically, object detection systems depended on feature-based techniques which included creating manually engineered features for each region, and then training of a shallow classifier such as SVM or logistic regression. The proliferation of powerful GPUs and availability of large datasets have made training deep neural networks practical for object detection. DNNs address almost all of the aforementioned challenges as they have the capacity to learn more complex representations of objects in images than shallow networks and eliminate the reliance on hand-engineered features. Most deep-learning-based object detection approaches today repurpose image classifiers by applying them to a sliding window across an input image. Some approaches such as regions with convolutional neural networks (RCNN) make region proposals using selective search instead of doing an exhaustive search to save computation, but it still generates over 2000 proposals per image. These approaches are in general very computationally expensive, and do not generate accurate bounding boxes for object detection. This past December, DigitalGlobe, CosmiQ Works and NVIDIA held a competition for developers to build and test algorithms against the vast SpaceNet imagery data to extract building footprints. Training data, including imagery and validated building footprint polygons were provided to the teams. They then trained and tuned their deep learning software to extract building footprints from a far larger set of imagery. We will discuss the techniques used, what is successful and where improvements are needed.
Presented by Chip Carr
Presented by Chip Carr
 0:05:00
0:05:00
 1:03:47
1:03:47
 0:01:00
0:01:00
 0:24:48
0:24:48
 0:15:41
0:15:41
 0:04:00
0:04:00
 0:02:42
0:02:42
 0:07:52
0:07:52
 0:49:22
0:49:22
 0:40:58
0:40:58
 0:36:12
0:36:12
 1:20:57
1:20:57
 0:28:23
0:28:23
 0:28:41
0:28:41
 0:07:51
0:07:51
 1:25:05
1:25:05
 0:05:53
0:05:53
 13:16:41
13:16:41
 1:17:11
1:17:11
 0:43:48
0:43:48
 0:22:21
0:22:21
 0:23:54
0:23:54
 0:05:19
0:05:19
 0:05:16
0:05:16