filmov
tv
A No-Code AI NLP Platform for Automated Document & Text Analysis.
Показать описание
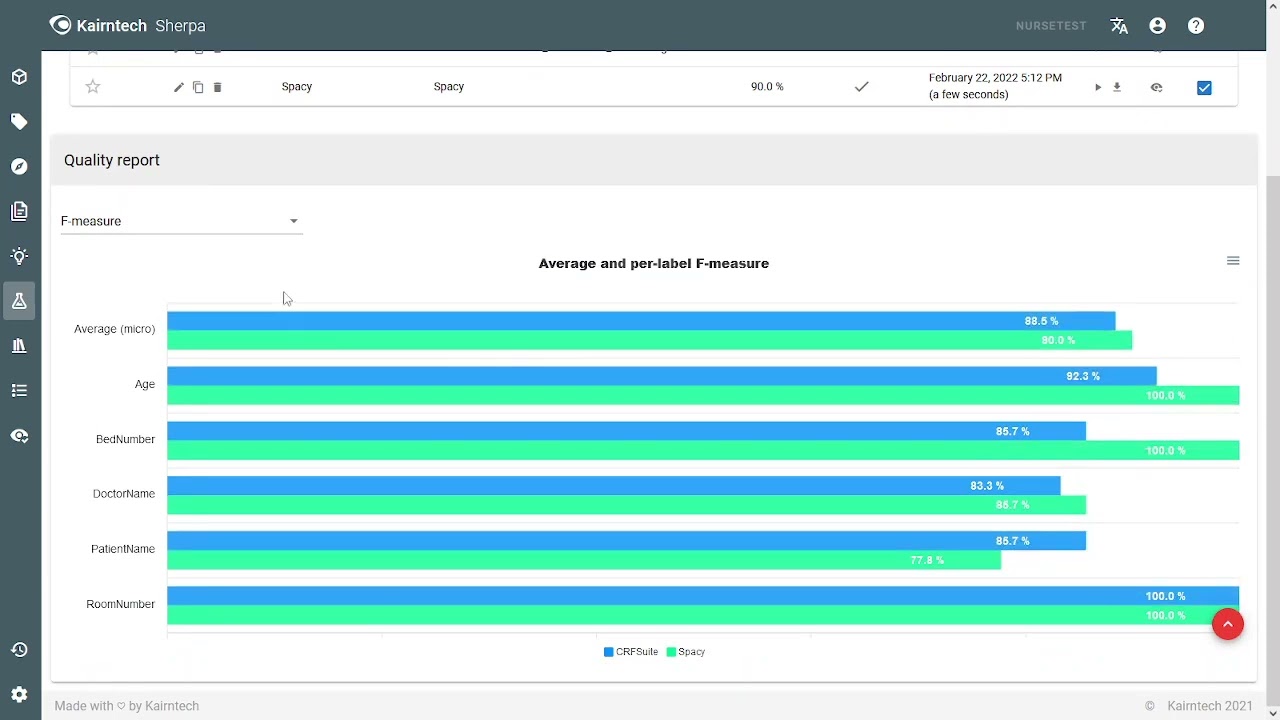
Kairntech is a collaborative NLP platform to annotate text data, to experiment with models and to create NLP pipelines with custom-build models, off-the-shelf models and technical components. Kairntech enables you to annotate text by highlighting elements with your mouse. While doing so the system learns in the background and then creates suggestions. This is called active learning. In documents that are not yet annotated, active learning enables you to accept or reject suggestions very quickly. It speeds up the process of creating the training dataset. If you already have annotated data you can import it and reduce or even avoid manual annotation. With the annotated data of the training dataset it is now possible to create models using different pre-packaged algorithms. These algorithms may be sophisticated and compute intensive for instance when they are based on deep learning algorithms with word embeddings. The objective is then to experiment with different algorithms, compare models and select the model that is most appropriate for your business case, and with the right balance between accuracy and performance. If you want to extend your training dataset, you may also use world knowledge like Wikidata to automatically annotate documents. Sometimes a single model may be enough to go into production, letting it run on new documents. But in the large majority of cases, it is necessary to create an NLP pipeline, combining custom-build models, off-the-shelf models and technical components to create, modify, delete text or annotations. In addition, technical components can be used to convert input documents or format the results to the required output format (XML, Excel, etc.). This process can be applied on other NLP tasks like text classification and on a broad range of document types and scenarios on customer verbatim, speech recordings, press documents, scientific papers, contracts and so on. Kairntech makes it really easy - even fun - to use. It is fast because you can build training datasets in hours. The results are embeddable using APIs. And last but not least you don’t have to be a data scientist to use the application, it is accessible to everyone.
 0:03:44
0:03:44
 0:00:26
0:00:26
 0:05:51
0:05:51
 0:12:00
0:12:00
 0:20:33
0:20:33
 0:01:01
0:01:01
 0:01:00
0:01:00
 0:01:00
0:01:00
 0:31:31
0:31:31
 0:20:13
0:20:13
 0:16:10
0:16:10
 2:55:23
2:55:23
 0:34:47
0:34:47
 0:00:22
0:00:22
 0:28:11
0:28:11
 0:05:49
0:05:49
 0:01:27
0:01:27
 0:14:15
0:14:15
 0:25:56
0:25:56
 0:23:35
0:23:35
 0:00:46
0:00:46
 0:05:48
0:05:48
 0:02:12
0:02:12
 0:00:29
0:00:29