filmov
tv
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Показать описание
Abstract:
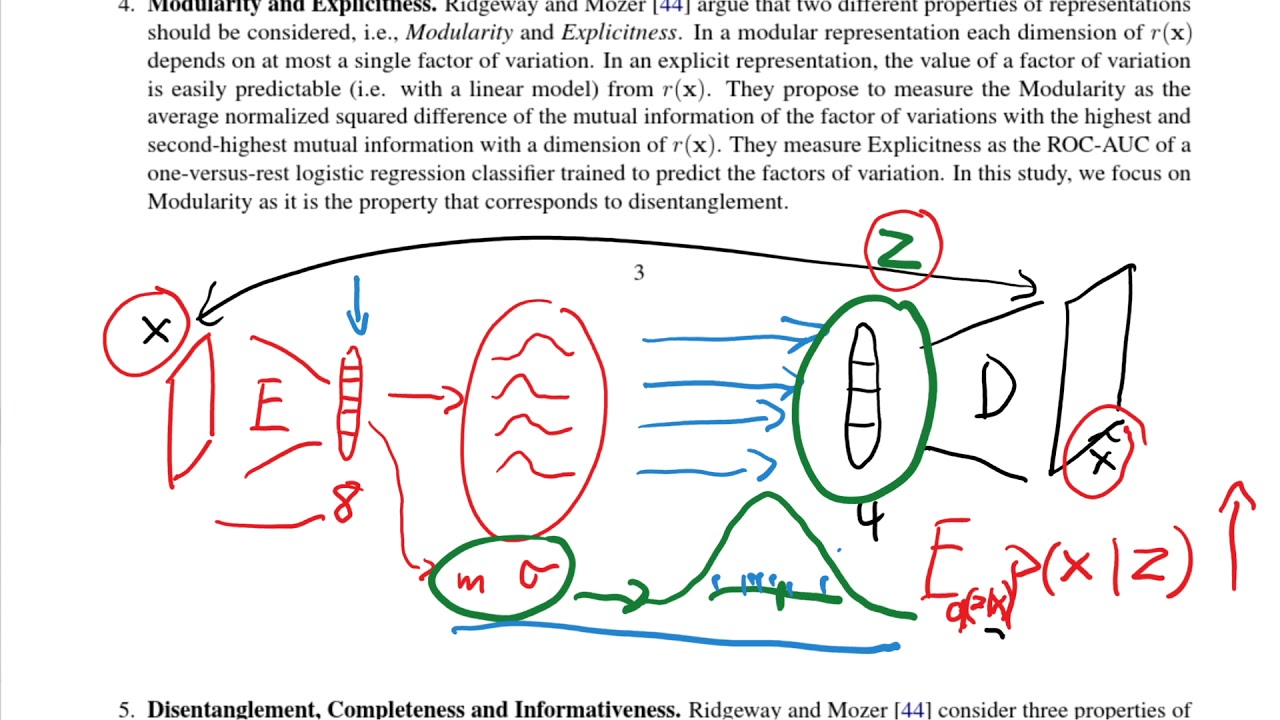
In recent years, the interest in unsupervised learning of disentangled representations has significantly increased. The key assumption is that real-world data is generated by a few explanatory factors of variation and that these factors can be recovered by unsupervised learning algorithms. A large number of unsupervised learning approaches based on auto-encoding and quantitative evaluation metrics of disentanglement have been proposed; yet, the efficacy of the proposed approaches and utility of proposed notions of disentanglement has not been challenged in prior work. In this paper, we provide a sober look on recent progress in the field and challenge some common assumptions.
We first theoretically show that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data. Then, we train more than 12000 models covering the six most prominent methods, and evaluate them across six disentanglement metrics in a reproducible large-scale experimental study on seven different data sets. On the positive side, we observe that different methods successfully enforce properties "encouraged" by the corresponding losses. On the negative side, we observe in our study that well-disentangled models seemingly cannot be identified without access to ground-truth labels even if we are allowed to transfer hyperparameters across data sets. Furthermore, increased disentanglement does not seem to lead to a decreased sample complexity of learning for downstream tasks.
These results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.
Authors:
Francesco Locatello, Stefan Bauer, Mario Lucic, Sylvain Gelly, Bernhard Schölkopf, Olivier Bachem
 0:27:45
0:27:45
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
 0:04:43
0:04:43
What do AEs learn? Challenging Common Assumptions in Unsupervised Anomaly Detection
 0:01:14
0:01:14
3 Common Examples of Challenging Assumptions at Work
 0:01:00
0:01:00
Challenging Your Assumptions: Critical Thinking 101 #shorts
 0:08:44
0:08:44
Why challenging assumptions is the way to go | Kevin Weijers | TEDxBreda
 0:03:52
0:03:52
The Astonishing Importance of Challenging Assumptions
 0:01:34
0:01:34
Creative Thinking Skills | Challenging Assumptions Activity
 0:01:25
0:01:25
Challenging Common Investment Assumptions: The Truth Revealed
 0:00:32
0:00:32
We think it helps us, but it hurts us.
![[EN] 17A -](https://i.ytimg.com/vi/LDQCD6G0lNQ/hqdefault.jpg) 2:30:54
2:30:54
[EN] 17A - Reverse plenary: challenging common assumptions for a sustainable future!
 0:01:19
0:01:19
6 Challenging Assumptions Exercises From Business
 0:05:47
0:05:47
Tina Seelig: Challenge Assumptions
 0:02:21
0:02:21
Making Assumptions | Critical Thinking
 0:00:30
0:00:30
The Shorts - Comment Ça Va: Challenging Common Assumptions #shorts
 0:01:40
0:01:40
Challenging Dangerous Assumptions by Andy Cohen
 0:01:04
0:01:04
Easiest Tip How To Challenge Assumptions Like A Pro
 0:01:11
0:01:11
Challenging assumptions to make Humanities better
 0:04:29
0:04:29
How to challenge assumptions at work?
 0:00:45
0:00:45
Unseen Assumptions: The Key to Truth?
 0:00:14
0:00:14
Challenging Assumptions: The Real Reason for the Gender Pay Gap
 0:00:18
0:00:18
Stop Making Assumptions in Your Questions: Investigate First!
 0:15:49
0:15:49
Challenging Assumptions
 0:29:30
0:29:30
Challenging Your Assumptions
 0:01:11
0:01:11
Challenging Assumptions: The Power of Questioning Our Beliefs
Комментарии