filmov
tv
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)
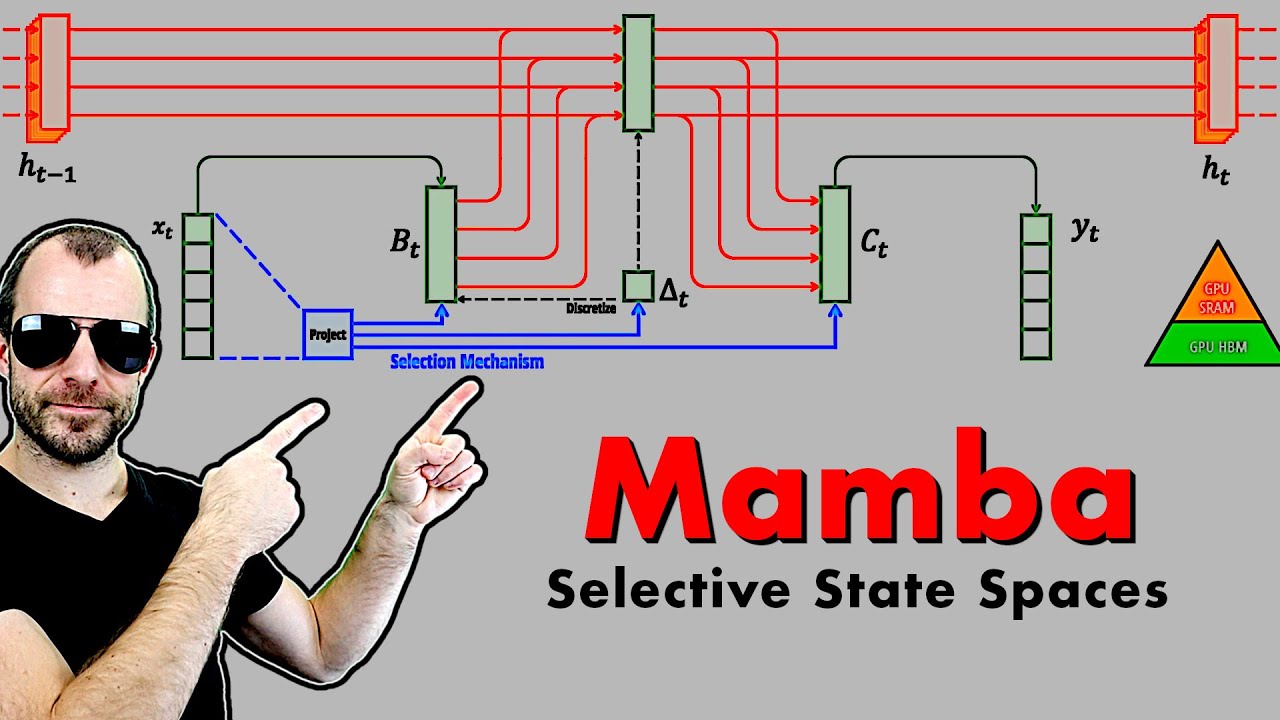
Показать описание
#mamba #s4 #ssm
OUTLINE:
0:00 - Introduction
0:45 - Transformers vs RNNs vs S4
6:10 - What are state space models?
12:30 - Selective State Space Models
17:55 - The Mamba architecture
22:20 - The SSM layer and forward propagation
31:15 - Utilizing GPU memory hierarchy
34:05 - Efficient computation via prefix sums / parallel scans
36:01 - Experimental results and comments
38:00 - A brief look at the code
Abstract:
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Authors: Albert Gu, Tri Dao
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
OUTLINE:
0:00 - Introduction
0:45 - Transformers vs RNNs vs S4
6:10 - What are state space models?
12:30 - Selective State Space Models
17:55 - The Mamba architecture
22:20 - The SSM layer and forward propagation
31:15 - Utilizing GPU memory hierarchy
34:05 - Efficient computation via prefix sums / parallel scans
36:01 - Experimental results and comments
38:00 - A brief look at the code
Abstract:
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Authors: Albert Gu, Tri Dao
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
 0:40:40
0:40:40
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)
 0:31:51
0:31:51
MAMBA from Scratch: Neural Nets Better and Faster than Transformers
 0:22:27
0:22:27
MAMBA and State Space Models explained | SSM explained
 0:16:01
0:16:01
Mamba - a replacement for Transformers?
 0:44:02
0:44:02
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 1:14:29
1:14:29
Mamba and S4 Explained: Architecture, Parallel Scan, Kernel Fusion, Recurrent, Convolution, Math
 0:16:20
0:16:20
Mamba, SSMs & S4s Explained in 16 Minutes
 0:12:43
0:12:43
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 0:44:23
0:44:23
Deep dive into how Mamba works - Linear-Time Sequence Modeling with SSMs - Arxiv Dives
 0:15:57
0:15:57
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (COLM Oral 2024)
 0:14:06
0:14:06
Mamba Might Just Make LLMs 1000x Cheaper...
![[Paper Review] Mamba:](https://i.ytimg.com/vi/JjxBNBzDbNk/hqdefault.jpg) 1:21:45
1:21:45
[Paper Review] Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 0:59:26
0:59:26
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 0:54:31
0:54:31
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 0:19:15
0:19:15
Mamba: Linear Time Sequence Modeling with Selective State Spaces
 0:04:02
0:04:02
Mamba Linear Time Sequence Modeling with Selective State Spaces
 0:31:31
0:31:31
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
![[Paper Review] Mamba:](https://i.ytimg.com/vi/fURRobLWkqc/hqdefault.jpg) 0:24:03
0:24:03
[Paper Review] Mamba: Linear-Time Sequence Modeling with Selective State Spaces
 1:04:42
1:04:42
Paper Reading Session 1 - Mamba: Linear Time Sequence Modelling with Selective State Spaces
 0:01:00
0:01:00
Mamba Architecture Lobotomy Kaisen
 0:54:39
0:54:39
Paper Club with Vahan - Mamba: Linear-Time Sequence Modelling with Selective State Spaces
![[DS Interface] Mamba:Linear-Time](https://i.ytimg.com/vi/Gg3T9ZDqyYY/hqdefault.jpg) 0:22:14
0:22:14
[DS Interface] Mamba:Linear-Time Sequence Modeling with Selective State Spaces
 1:20:59
1:20:59
Mamba sequence model - part 1
 0:38:11
0:38:11
State Space Models (S4, S5, S6/Mamba) Explained
Комментарии