filmov
tv
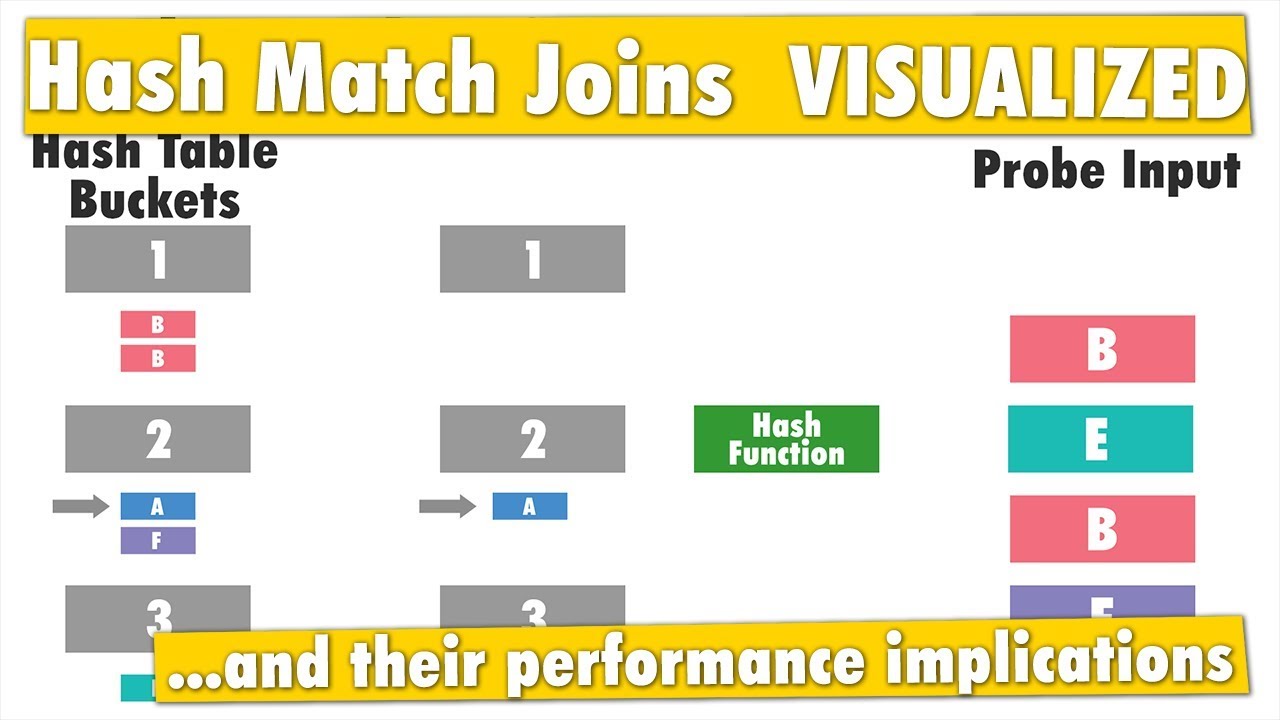
Hash Match Join Internals in SQL Server
Показать описание
Hash Match Joins can join almost any data thrown at them. In this video learn about how the hash match join algorithm works and what seeing hash match joins in your execution plans means for performance of your queries.
Related blog post about Hash Match Joins:
Going further in-depth with hash match joins:
Follow me on Twitter:
Related blog post about Hash Match Joins:
Going further in-depth with hash match joins:
Follow me on Twitter:
 0:05:37
0:05:37
Hash Match Join Internals in SQL Server
 0:15:55
0:15:55
How do nested loop, hash, and merge joins work? Databases for Developers Performance #7
 0:06:13
0:06:13
SQL Interview Question - What is a Hash Match Join in SQL Server?
 0:00:14
0:00:14
Hash Join
 0:07:16
0:07:16
Merge Join Internals in SQL Server
 0:03:06
0:03:06
Mastering the Basics of SQL Server Query Optimization - Hash Match Operator
 0:11:08
0:11:08
How nested loop, hash, and merge joins work.
 0:00:16
0:00:16
Hash Join Semi
 1:43:06
1:43:06
Hash Match, the Operator - Part 1
 0:01:18
0:01:18
Mastering the Basics of SQL Server Query Optimization - Joins The Hash Join
 0:22:09
0:22:09
Part 4 - Hash Match Joins in SQL SERVER | SQL Server
 0:03:01
0:03:01
Databases: query performance gains by removing operator hash match inner join
 1:34:38
1:34:38
Hash Match, the Operator - Part 2
 0:23:50
0:23:50
Hashing and Hash Match operator in SQL Server (Hebrew edition)
 0:02:36
0:02:36
SQL server chooses hash match over merge join but the input fields to join should be sorted
 0:08:47
0:08:47
Joins in SQL Server Execution Plans
 0:16:57
0:16:57
A Little About Hash Join Spills And Bailouts In SQL Server
 0:04:07
0:04:07
Databases: Hash Match inner join in simple query with in statement (2 Solutions!!)
 0:04:01
0:04:01
Como funciona o Hash Join?
 1:16:38
1:16:38
CMU Database Systems - 12 Hash Joins & Aggregations (Fall 2017)
 0:08:41
0:08:41
Part 1 - Logical Joins Vs Physical Joins in SQL SERVER
 0:07:37
0:07:37
The Importance of Nested Loops Joins in SQL
 0:03:11
0:03:11
Databases: Execution Plan Basics -- Hash Match Confusion (3 Solutions!!)
 0:04:34
0:04:34
Why is my HASH JOIN broken?
Комментарии