filmov
tv
Mastering Regex for XML Selection: Extracting Elements with Python

Показать описание
Learn how to effectively use Regex in Python to extract XML elements between specific tags like `BYPASS` and `WAK`. This guide simplifies the process and provides practical examples for better understanding.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Regex XML Selection Extract Element
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Mastering Regex for XML Selection: Extracting Elements with Python
When working with XML data in Python, there are times you might need to isolate specific sections of your XML code. This is often done using regular expressions, or regex, which allows you to search and manipulate strings based on specific patterns. If you’re facing difficulty extracting elements between the tags “BYPASS 0 0 0” and “WAK 0 0”, you’re in the right place! In this post, we’ll break down the regex syntax and how to implement it using Python.
The Problem
Imagine you have an XML document and you want to extract a section that starts at BYPASS 0 0 0 and ends at WAK 0 0. However, it appears you’re struggling with the regex syntax in Python, leaving you with incorrect selections.
The Solution
To successfully extract the needed data, you'll need to use a specific regex pattern that captures everything from the starting point to the endpoint. Here's how to do it.
Understanding the Regex Pattern
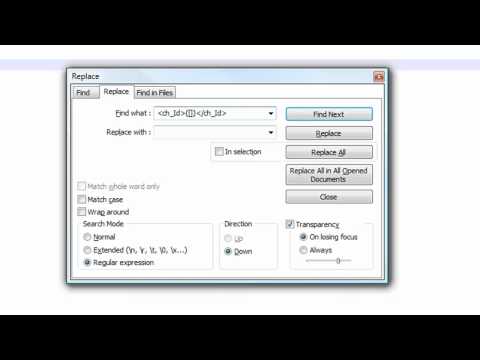
The regex pattern we will use is:
[[See Video to Reveal this Text or Code Snippet]]
Let’s break down this pattern:
(?s): This is a flag that indicates that the dot (.) will match any character, including newline characters. This is essential when dealing with multi-line strings.
(BYPASS 0 0 0: This specifies the start of our desired capture – it matches the literal string BYPASS 0 0 0.
.*?: This part means "zero or more" of any characters, allowing us to capture everything in between the start and end points. The ? makes it non-greedy, meaning it will match the shortest possible string that satisfies the condition.
WAK 0 0): This specifies the endpoint and closes our capturing group. It matches the literal string WAK 0 0.
Using Regex in Python
Once you've defined your regex pattern, you can use it to extract the desired sections from your XML string. Here’s how to implement the regex using Python’s re module:
1. Example Code to Extract the Data
[[See Video to Reveal this Text or Code Snippet]]
Key Takeaways
Use (?s) to ensure that your regex matches across multiple lines.
Always test your regex with sample data to ensure it aligns with your expectations.
Conclusion
Extracting specific elements from XML using regex in Python can be a potent tool in your data processing arsenal. With the correct understanding of regex patterns and Python’s capabilities, you can effectively isolate and work with the data you need.
If you still have questions or need further clarifications, feel free to reach out in the comments below! Happy coding!
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Regex XML Selection Extract Element
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Mastering Regex for XML Selection: Extracting Elements with Python
When working with XML data in Python, there are times you might need to isolate specific sections of your XML code. This is often done using regular expressions, or regex, which allows you to search and manipulate strings based on specific patterns. If you’re facing difficulty extracting elements between the tags “BYPASS 0 0 0” and “WAK 0 0”, you’re in the right place! In this post, we’ll break down the regex syntax and how to implement it using Python.
The Problem
Imagine you have an XML document and you want to extract a section that starts at BYPASS 0 0 0 and ends at WAK 0 0. However, it appears you’re struggling with the regex syntax in Python, leaving you with incorrect selections.
The Solution
To successfully extract the needed data, you'll need to use a specific regex pattern that captures everything from the starting point to the endpoint. Here's how to do it.
Understanding the Regex Pattern
The regex pattern we will use is:
[[See Video to Reveal this Text or Code Snippet]]
Let’s break down this pattern:
(?s): This is a flag that indicates that the dot (.) will match any character, including newline characters. This is essential when dealing with multi-line strings.
(BYPASS 0 0 0: This specifies the start of our desired capture – it matches the literal string BYPASS 0 0 0.
.*?: This part means "zero or more" of any characters, allowing us to capture everything in between the start and end points. The ? makes it non-greedy, meaning it will match the shortest possible string that satisfies the condition.
WAK 0 0): This specifies the endpoint and closes our capturing group. It matches the literal string WAK 0 0.
Using Regex in Python
Once you've defined your regex pattern, you can use it to extract the desired sections from your XML string. Here’s how to implement the regex using Python’s re module:
1. Example Code to Extract the Data
[[See Video to Reveal this Text or Code Snippet]]
Key Takeaways
Use (?s) to ensure that your regex matches across multiple lines.
Always test your regex with sample data to ensure it aligns with your expectations.
Conclusion
Extracting specific elements from XML using regex in Python can be a potent tool in your data processing arsenal. With the correct understanding of regex patterns and Python’s capabilities, you can effectively isolate and work with the data you need.
If you still have questions or need further clarifications, feel free to reach out in the comments below! Happy coding!
 0:01:37
0:01:37
 0:00:54
0:00:54
 0:02:56
0:02:56
 0:01:37
0:01:37
 0:02:04
0:02:04
 0:01:41
0:01:41
 0:15:41
0:15:41
 0:57:55
0:57:55
 0:08:23
0:08:23
 0:13:21
0:13:21
 0:10:54
0:10:54
 0:06:07
0:06:07
 0:02:09
0:02:09
 0:05:05
0:05:05
 0:34:17
0:34:17
 0:57:14
0:57:14
 0:02:02
0:02:02
 0:10:15
0:10:15
 0:10:08
0:10:08
 0:01:06
0:01:06
 0:03:21
0:03:21
 0:01:24
0:01:24
 0:02:17
0:02:17
 1:02:56
1:02:56