filmov
tv
Understanding Code You Didn't Write // Code Review

Показать описание
CHAPTERS
0:00 - Resuming from last time
1:20 - Reading code you didn't write
8:27 - Easily find the entry point
10:51 - How the program works
15:32 - Code should be self-documenting ✔
17:14 - Comments in code to control tools ❌
17:55 - static_cast and dynamic_cast
20:19 - structs vs classes: when to use what
24:19 - Why prefixing member variables is useful
This video is sponsored by Brilliant.
#CodeReview
 0:27:15
0:27:15
Understanding Code You Didn't Write // Code Review
 0:06:17
0:06:17
2 Strategies for Reading Code You Didn’t Write
 0:01:51
0:01:51
Writing code you don't understand.
 0:02:56
0:02:56
Don't write clever code.
 0:05:13
0:05:13
Using ChatGPT to understand and review code written by others, to write better code and test it also
 0:13:37
0:13:37
How Senior Programmers ACTUALLY Write Code
 0:00:37
0:00:37
Please, Write REUSABLE Code
 0:07:24
0:07:24
Don’t ask AI to write your code
 0:00:57
0:00:57
Here's What REALLY Happens When You Reach This Point
 0:11:58
0:11:58
Stop Trying To Write 'Perfect' Code
 0:10:05
0:10:05
Will Your Code Write Itself?
 0:00:16
0:00:16
Writing Code To Read To Me To Learn Faster #learning #tech #coding
 0:00:53
0:00:53
5 Tips For Writing Better Code
 0:00:10
0:00:10
When you wait for ChatGPT to finish writing code... you should be writing
 0:07:33
0:07:33
How To Write Code You Love (& Still Finish On Time)
 0:08:39
0:08:39
Don't ever write Python code like this
 0:01:01
0:01:01
How to Write Better Code
 0:20:47
0:20:47
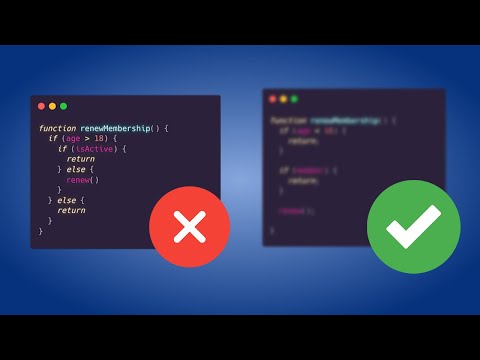
How Software Engineers Can Write Better Code
 0:07:41
0:07:41
Cleaner Code: 3 Ways You Can Write Cleaner Code
 0:09:57
0:09:57
How To Get Good at Programming - Without Tutorial Hell...
 0:04:10
0:04:10
How to Write Clean Code Even a Baby Can Understand - Part 1
 0:16:36
0:16:36
5 RULES to Write Better Code
 0:01:01
0:01:01
Have you ever written all your methods in only 4 lines?
 0:23:32
0:23:32
📚 How to Improve as a Programmer - DON'T WRITE MORE CODE, READ MORE
Комментарии