filmov
tv
DPDK Acceleration with GPU - Elena Agostini, Nvidia, Cliff Burdick, ViaSat & Shahaf Shuler, Mellanox

Показать описание
DPDK Acceleration with GPU - Elena Agostini, Nvidia, Cliff Burdick, ViaSat & Shahaf Shuler, Mellanox
Speakers: Cliff Burdick, Shahaf Shuler, Elena Agostini
We demonstrate the applicability of GPUs as packet processing accelerators, especially for compute-intensive tasks. The following techniques and challenges will be discussed:
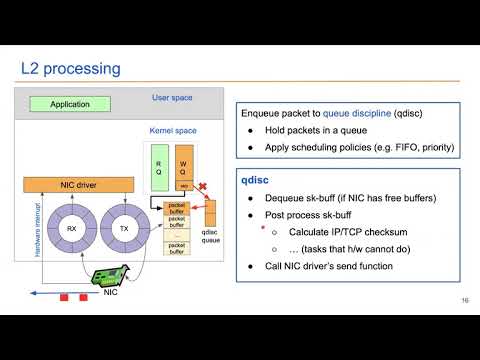
- Allowing GPUDirect RDMA Rx and Tx, in which the packets are exchanged directly between the NIC and the GPU.
- For zero-copy, mbuf data needs to be located in a memory usable by both devices, therefore the external buffer feature of mbuf is used, with the external buffer located in GPU on-chip memory or GPU-addressable CPU memory.
- Rx queue can optionally be configured to split incoming packets between CPU and GPU memory which allows CPU processing of packet headers and GPU direct access to packet payload.
Various applications are demonstrating these techniques, including:
- An L2 forwarding application using a CUDA kernel.
- An application matching flows to process on the GPU, with the use of CPU/GPU header/data split.
- Modified version of testpmd using GPU memory
Speakers: Cliff Burdick, Shahaf Shuler, Elena Agostini
We demonstrate the applicability of GPUs as packet processing accelerators, especially for compute-intensive tasks. The following techniques and challenges will be discussed:
- Allowing GPUDirect RDMA Rx and Tx, in which the packets are exchanged directly between the NIC and the GPU.
- For zero-copy, mbuf data needs to be located in a memory usable by both devices, therefore the external buffer feature of mbuf is used, with the external buffer located in GPU on-chip memory or GPU-addressable CPU memory.
- Rx queue can optionally be configured to split incoming packets between CPU and GPU memory which allows CPU processing of packet headers and GPU direct access to packet payload.
Various applications are demonstrating these techniques, including:
- An L2 forwarding application using a CUDA kernel.
- An application matching flows to process on the GPU, with the use of CPU/GPU header/data split.
- Modified version of testpmd using GPU memory
 0:38:08
0:38:08
 0:28:10
0:28:10
 0:52:36
0:52:36
 0:32:05
0:32:05
 0:07:25
0:07:25
 0:22:37
0:22:37
 0:29:05
0:29:05
 0:31:50
0:31:50
 0:22:45
0:22:45
 0:27:04
0:27:04
 0:12:56
0:12:56
 0:02:19
0:02:19
 0:19:21
0:19:21
 0:27:17
0:27:17
 0:32:13
0:32:13
 0:11:41
0:11:41
 0:05:21
0:05:21
![[2017] Improve VNF](https://i.ytimg.com/vi/amlhowbtlSw/hqdefault.jpg) 0:30:31
0:30:31
 0:54:46
0:54:46
 0:50:42
0:50:42
 0:44:54
0:44:54
 0:02:00
0:02:00
 0:28:42
0:28:42
 0:19:14
0:19:14