filmov
tv
The Insanity Of Linux's Regular Expressions

Показать описание
Become A Channel Member:
SOCIALS
----------------
SOCIALS
----------------
 0:02:33
0:02:33
TempleOS in 100 Seconds
 0:01:55
0:01:55
The Madness behind the Linux Source Code Comments
 0:00:37
0:00:37
5 reasons Linux is the best OS for coding/ Programming #linux #programming
 0:00:54
0:00:54
Insane Linux Distributions
 0:00:53
0:00:53
Windows user vs Linux user customizing their desktop
 0:00:41
0:00:41
Why Linux is best Operating System Ever | Linux Operating System
 0:00:36
0:00:36
Uncovering the INSANE Functionality of a Linux SCRATCHPAD #shorts
 0:00:40
0:00:40
Funny Linux Commands - How to Kill Child With Fork | Search History | Operating Systems | #shorts
 0:00:57
0:00:57
why you should install and use Linux Mint
 0:00:15
0:00:15
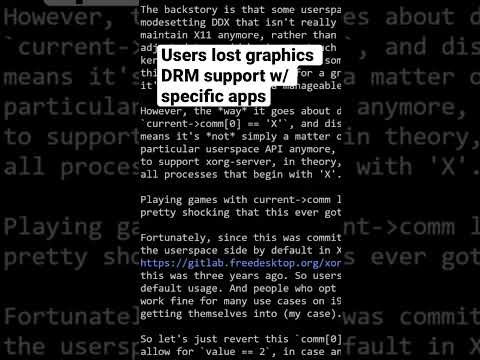
This CODE broke the Linux Kernel’s ability to use GPU DRM
 0:00:19
0:00:19
THERE are MANY types of LINUX Kernels
 0:14:32
0:14:32
Top 10 INSANE Linux Terminal Applications You Should Be Using! (Command Line Sorcery)
 0:00:40
0:00:40
How do you say 'chmod' the linux/unix system utility #shorts
 0:00:06
0:00:06
linux vs windows #hacking #linux #windows #vs #cybersecurity #shorts #youtubeshorts #youtube #hello
 0:00:31
0:00:31
Arch Linux Insane Boot Time! 11.210s
 0:00:18
0:00:18
Best Linux Distributions for programmers #linux #programming
 0:11:19
0:11:19
Are Linux Smartphones about to KILL Android?
 0:01:02
0:01:02
Insane Arch Linux responsiveness with zen-kernel
 0:00:11
0:00:11
The #Linux kernel is written on a C programming language - interesting facts about OS
 0:00:14
0:00:14
Must Read Book For Understanding Linux Internals #shorts
 0:00:16
0:00:16
Why Am I Loving This Insane Linux Video Editor 🤯🤯🤯 Is It Really That Great 🥺🥺🥺
 0:00:32
0:00:32
AAA Games on Linux
 0:22:59
0:22:59
I forced EVERYONE to use Linux
 0:20:29
0:20:29
I Installed Linux On a Playstation 2!
Комментарии