filmov
tv
Imbalanced Data Classification

Показать описание
Imbalanced data is a disproportionate number of data points with discrete labels and can be a big challenge to develop an accurate classifier. A classifier attempts to find the data boundary where one class ends and the other begins. [[Main/ClassificationOverview|Classification]] is used to create these boundaries when the desired output (label) is discrete such as 0/1, Yes/No, 1,2,3,4,5, or Normal/Abnormal. Regression is used when the desired output (label) is continuous.
Imbalanced data can give biased predictions for classification when there is a minority class. This tutorial demonstrates how to deal with imbalanced data.
Imbalanced data can give biased predictions for classification when there is a minority class. This tutorial demonstrates how to deal with imbalanced data.
 0:11:48
0:11:48
How to handle imbalanced datasets in Python
 0:13:44
0:13:44
Handling Imbalanced Dataset in Machine Learning: Easy Explanation for Data Science Interviews
 0:38:26
0:38:26
Handling imbalanced dataset in machine learning | Deep Learning Tutorial 21 (Tensorflow2.0 & Pyt...
 0:37:58
0:37:58
Imbalanced Data Classification
 0:10:44
0:10:44
This is why you should care about unbalanced data .. as a data scientist
 0:09:09
0:09:09
What Is Balanced And Imbalanced Dataset How to handle imbalanced datasets in ML DM by Mahesh Huddar
 0:05:51
0:05:51
HOW TO DEAL WITH IMBALANCED DATA ? | Classification | Machine Learning
 0:09:15
0:09:15
Machine Learning Classification How to Deal with Imbalanced Data ❌ Practical ML Project with Python...
 1:34:22
1:34:22
Project 38: Cyber Bullying Detection Using Machine Learning
 0:13:00
0:13:00
Machine Learning with Imbalanced Data - Part 2 (Cost-sensitive Learning)
 0:48:53
0:48:53
Webinar 'Evaluating XGBoost for balanced and Imbalanced datasets'
 0:04:24
0:04:24
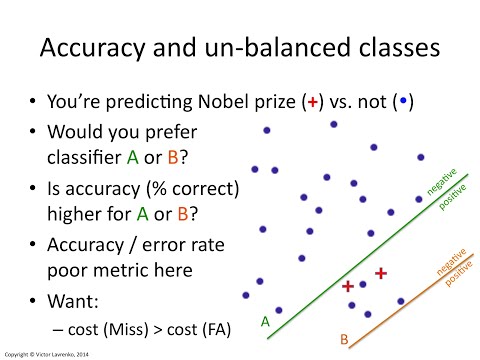
IAML2.22: Classification accuracy and imbalanced classes
 0:00:33
0:00:33
How to Deal With Imbalanced Classification
 0:13:01
0:13:01
Tutorial 45-Handling imbalanced Dataset using python- Part 1
 0:27:45
0:27:45
Natalie Hockham: Machine learning with imbalanced data sets
 0:04:05
0:04:05
Learning Deep Representation for Imbalanced Classification
 0:22:13
0:22:13
How To Evaluate Classifiers with Imbalanced Dataset Part A Fundamentals, Metrics, Synthetic Dataset
 0:13:49
0:13:49
Binary Classification on Imbalanced Dataset, by Xingyu Wang&Zhenyu Chen
 0:36:44
0:36:44
148 - 7 techniques to work with imbalanced data for machine learning in python
 1:13:22
1:13:22
Dealing with Imbalanced Datasets in ML Classification Problems | DataHour by Damini Dasgupta
 0:11:19
0:11:19
SMOTE (Synthetic Minority Oversampling Technique) for Handling Imbalanced Datasets
 0:30:54
0:30:54
Live 2020-02-17!!! Imbalanced Data and Post-Hoc Tests
 0:23:10
0:23:10
5 ways to work with imbalanced data | Imbalanced dataset machine learning | Imbalanced data
 0:01:52
0:01:52
Imbalanced data classification with Python
Комментарии