filmov
tv
This is why understanding database concurrency control is important

Показать описание
the two articles I found
 0:03:47
0:03:47
What is a database in under 4 minutes
 0:12:11
0:12:11
Learn What is Database | Types of Database | DBMS
 0:03:55
0:03:55
What is Database & Database Management System DBMS | Intro to DBMS
 0:05:32
0:05:32
Database Tutorial for Beginners
 0:07:54
0:07:54
What is a Relational Database?
 0:05:22
0:05:22
Database vs Data Warehouse vs Data Lake | What is the Difference?
 0:05:38
0:05:38
What is database | DBMS | Lec-2 | Bhanu Priya
 0:28:34
0:28:34
Learn Database Normalization - 1NF, 2NF, 3NF, 4NF, 5NF
 0:00:40
0:00:40
Day 24 | SQL in Data Science - Explained! @Nxtivia #100dayschallenge #datascience
 0:25:17
0:25:17
SQL Server Tutorial For Beginners | SQL Server: Understanding Database Fundamentals | Simplilearn
 0:17:06
0:17:06
Introduction To DBMS - Database Management System | What Is DBMS? | DBMS Explanation | Simplilearn
 0:06:19
0:06:19
Relational Database Relationships (Updated)
 0:04:46
0:04:46
What is a database schema?
 0:05:17
0:05:17
What Is Database Management System ? | What Is DBMS ?
 0:03:56
0:03:56
What is a Graph Database?
 0:07:06
0:07:06
Database vs Spreadsheet - Advantages and Disadvantages
 8:07:20
8:07:20
Database Design Course - Learn how to design and plan a database for beginners
 0:01:27
0:01:27
What Is SQL? | SQL Explained in 2 Minutes | What Is SQL Database? | SQL For Beginners |Simplilearn
 0:27:17
0:27:17
Understand Database Security Concepts
 0:07:04
0:07:04
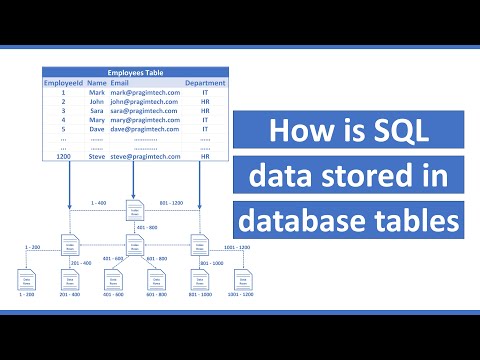
How is data stored in sql database
 0:00:57
0:00:57
What is Normalization in SQL, and Why is it Important ? | Database Management System | DBMS #shorts
 0:08:11
0:08:11
Basic Concept of Database Normalization - Simple Explanation for Beginners
 0:00:32
0:00:32
Database Sharting Explained
 0:22:21
0:22:21
Lec 1: Introduction to DBMS | Database Management System
Комментарии