filmov
tv
Hash Tables

Показать описание
Today we went over hash tables. Their strength is O(1) insert, search, and delete. These are the most common operations, and so if that's all you need from a data structure, it should be your go-to move.
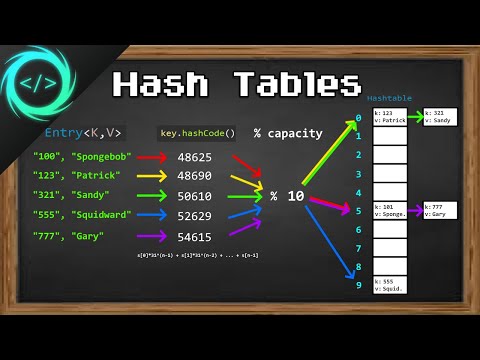
A hash table is basically a giant array that you immediately jump to the right spot to insert/search/delete to by doing the following operation: key % SIZE. A key is the value you're using to insert or search a database for, like a Social Security Number (which UCSD used to use for our student IDs) or Student ID. Sometimes all you insert is the key, but usually there's a "value" associated with a key, like a full student record. You use their student ID to look them up in the database, right, and then it returns the whole record. That's called a key/value pair.
All four of the basic variants of hash tables are the same at the beginning - you jump to whichever element of the array that key % SIZE is. Where they differ is what happens when you get a "collision", meaning something else is already there.
Variant 1) Linear Probing. If one spot is full, check the next spot to the right. (If you hit the edge of the table, wrap back to 0 using modulus.)
Variant 2) Quadratic Probing. Instead of going +1 to the right, +1 to the right, +1 to the right, you go +1 to the right, +4 to the right, +9 to the right, +16 to the right. Kind of sucks since it can't pass 50% load (load is what percent full the table is).
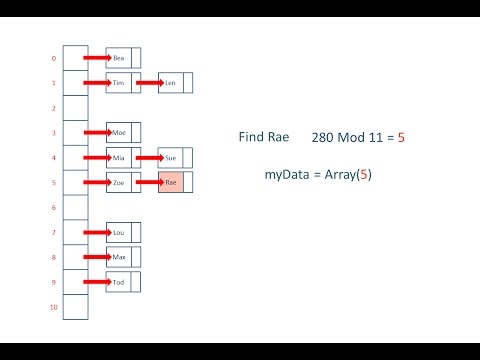
Variant 3) Double Hashing (very common). When doing double hashing, your table has to be a prime number in size, and you also compute a number called R that is another prime number smaller than it (often the next smaller, like 7 for 11). Rather than +1 to the right each time, you go f(key) to the right, where f(x) = 1+(x%R).
So for example if you hash 42 to in a hash table of size 13 (R = 11), it would hash to bucket 3 (42 % 13 = 3). If the spot was open, we're done. If there was a collision, we'd move 1+(42%11)=10 buckets to the right each time, going +10, +10, +10.
4) Finally, there is chaining, which is easy to write. You basically just make an array of BSTs. So you hash to whatever bucket as usual (key % SIZE) and then call insert on the BST there. Some people use linked lists, but BSTs give better worst case performance.
A hash table is basically a giant array that you immediately jump to the right spot to insert/search/delete to by doing the following operation: key % SIZE. A key is the value you're using to insert or search a database for, like a Social Security Number (which UCSD used to use for our student IDs) or Student ID. Sometimes all you insert is the key, but usually there's a "value" associated with a key, like a full student record. You use their student ID to look them up in the database, right, and then it returns the whole record. That's called a key/value pair.
All four of the basic variants of hash tables are the same at the beginning - you jump to whichever element of the array that key % SIZE is. Where they differ is what happens when you get a "collision", meaning something else is already there.
Variant 1) Linear Probing. If one spot is full, check the next spot to the right. (If you hit the edge of the table, wrap back to 0 using modulus.)
Variant 2) Quadratic Probing. Instead of going +1 to the right, +1 to the right, +1 to the right, you go +1 to the right, +4 to the right, +9 to the right, +16 to the right. Kind of sucks since it can't pass 50% load (load is what percent full the table is).
Variant 3) Double Hashing (very common). When doing double hashing, your table has to be a prime number in size, and you also compute a number called R that is another prime number smaller than it (often the next smaller, like 7 for 11). Rather than +1 to the right each time, you go f(key) to the right, where f(x) = 1+(x%R).
So for example if you hash 42 to in a hash table of size 13 (R = 11), it would hash to bucket 3 (42 % 13 = 3). If the spot was open, we're done. If there was a collision, we'd move 1+(42%11)=10 buckets to the right each time, going +10, +10, +10.
4) Finally, there is chaining, which is easy to write. You basically just make an array of BSTs. So you hash to whatever bucket as usual (key % SIZE) and then call insert on the BST there. Some people use linked lists, but BSTs give better worst case performance.
 0:03:52
0:03:52
 0:13:56
0:13:56
 0:06:25
0:06:25
 0:13:26
0:13:26
 0:18:40
0:18:40
 0:07:37
0:07:37
 0:18:47
0:18:47
 0:24:54
0:24:54
 0:30:23
0:30:23
 0:00:54
0:00:54
 0:17:52
0:17:52
 0:12:45
0:12:45
 0:33:52
0:33:52
![#032 [Data Structures]](https://i.ytimg.com/vi/mZFuZHOESEY/hqdefault.jpg) 0:13:48
0:13:48
 0:00:58
0:00:58
 0:05:15
0:05:15
 0:09:50
0:09:50
 0:20:16
0:20:16
 0:00:53
0:00:53
 0:25:51
0:25:51
 0:08:29
0:08:29
 0:16:09
0:16:09
 0:52:55
0:52:55
 0:10:10
0:10:10