filmov
tv
SQL Server Query Tuning Series- The Hidden Cause of Query Performance Nightmares @jbswiki #sqlserver

Показать описание
SQL Server Query Tuning Series - SQL Server Cardinality Estimation: The Hidden Cause of Query Performance Nightmares @jbswiki #sqlserverquerytuning
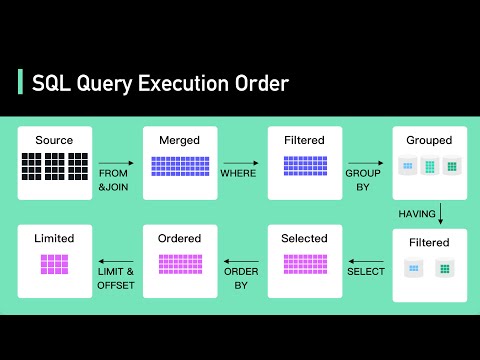
📈 The Power of Cardinality Estimation:
Our quest begins with an exploration of cardinality estimation, the behind-the-scenes maestro of SQL Server's query optimization process. Picture this: you have a query that needs to fetch data from your database. Before it even executes, SQL Server's query optimizer steps in to devise the best possible plan to fetch that data as swiftly as possible. But here's the catch - the optimizer relies heavily on cardinality estimates. So, what exactly is cardinality estimation, and why does it matter?
Cardinality estimation is the process by which SQL Server makes educated guesses about how many rows will be returned by different parts of your query. It's like trying to predict the weather - you need data and models to make an accurate forecast. In the world of SQL Server, statistics are the data, and the optimizer's models are the algorithms it uses to make these predictions.
📊 Statistics Histogram Demystified:
To understand cardinality estimation, we need to dive deeper into the world of statistics, particularly the statistics histogram. Think of statistics as the roadmaps that SQL Server uses to navigate through your data. These roadmaps include information about the distribution of data within columns, indexes, and tables.
The statistics histogram, in this context, is a critical component of statistics. It's like a magnifying glass that zooms in on the details of data distribution. Imagine you're planning a road trip, and you have a map of the entire country. That's your statistics. Now, imagine you have a histogram that zooms in on a specific city, showing you the traffic patterns, road conditions, and landmarks. That's your statistics histogram.
In SQL Server, the optimizer relies heavily on the statistics histogram to make decisions about how to execute your queries. When your query's predicates align perfectly with the histogram, it's like having a GPS guiding you turn by turn on the optimal route. The optimizer can make accurate predictions about the number of rows that will match your query conditions, leading to efficient query plans.
But what happens when your predicates don't align perfectly with the histogram? 🧐
❌ When Predicates Go Astray:
This is where the plot thickens. In many real-world scenarios, the predicates used in your queries may not have a direct match in the statistics histogram. It's like trying to find your way in an unfamiliar city with a vague map that doesn't quite match the streets and landmarks you encounter.
When this happens, the optimizer has to make educated guesses about the number of rows that will be returned. These guesses are based on patterns and statistical information, but they can be far from perfect. It's like trying to estimate the number of people attending a massive event by looking at a small sample of attendees. Sometimes, your estimate will be spot on, but other times, it will be way off the mark.
As a result, your SQL Server can choose suboptimal execution plans that lead to slow query performance. This is where the nightmare begins. You might find yourself scratching your head, wondering why a seemingly simple query is taking forever to complete. The culprit? Misplaced cardinality estimates.
⏳ The Perils of Outdated Statistics:
But wait, there's more to the cardinality estimation story. It's not just about the accuracy of estimates; it's also about the freshness of the data. Imagine trying to plan your week with a calendar from five years ago. Outdated statistics can have a similar effect on your SQL Server's understanding of your data.
Statistics become outdated over time as data distributions change. This can happen due to data inserts, updates, and deletes. If your statistics haven't been updated to reflect these changes, your cardinality estimates can be way off base.
Think of it like this: If your statistics are stuck in the past, your SQL Server is essentially making decisions based on outdated maps. It's like trying to find your way in a city that has completely transformed over the years. The roads have changed, new landmarks have emerged, but your GPS is stuck in 2016.
We'll explore the importance of keeping your statistics up-to-date and show you how to do it manually or automatically. This is a crucial step in preventing query performance nightmares caused by outdated information.
🤝 Join the Discussion:
We believe that learning is a collaborative journey. Your insights, experiences, and questions are invaluable to our community. So, as you watch this video, don't hesitate to share your thoughts and join the discussion in the comments section below. Let's learn and grow together as a community of data enthusiasts and SQL Server aficionados.
JBSWiki - Your Trusted Source for Data-Driven Excellence. 📊🔍
📈 The Power of Cardinality Estimation:
Our quest begins with an exploration of cardinality estimation, the behind-the-scenes maestro of SQL Server's query optimization process. Picture this: you have a query that needs to fetch data from your database. Before it even executes, SQL Server's query optimizer steps in to devise the best possible plan to fetch that data as swiftly as possible. But here's the catch - the optimizer relies heavily on cardinality estimates. So, what exactly is cardinality estimation, and why does it matter?
Cardinality estimation is the process by which SQL Server makes educated guesses about how many rows will be returned by different parts of your query. It's like trying to predict the weather - you need data and models to make an accurate forecast. In the world of SQL Server, statistics are the data, and the optimizer's models are the algorithms it uses to make these predictions.
📊 Statistics Histogram Demystified:
To understand cardinality estimation, we need to dive deeper into the world of statistics, particularly the statistics histogram. Think of statistics as the roadmaps that SQL Server uses to navigate through your data. These roadmaps include information about the distribution of data within columns, indexes, and tables.
The statistics histogram, in this context, is a critical component of statistics. It's like a magnifying glass that zooms in on the details of data distribution. Imagine you're planning a road trip, and you have a map of the entire country. That's your statistics. Now, imagine you have a histogram that zooms in on a specific city, showing you the traffic patterns, road conditions, and landmarks. That's your statistics histogram.
In SQL Server, the optimizer relies heavily on the statistics histogram to make decisions about how to execute your queries. When your query's predicates align perfectly with the histogram, it's like having a GPS guiding you turn by turn on the optimal route. The optimizer can make accurate predictions about the number of rows that will match your query conditions, leading to efficient query plans.
But what happens when your predicates don't align perfectly with the histogram? 🧐
❌ When Predicates Go Astray:
This is where the plot thickens. In many real-world scenarios, the predicates used in your queries may not have a direct match in the statistics histogram. It's like trying to find your way in an unfamiliar city with a vague map that doesn't quite match the streets and landmarks you encounter.
When this happens, the optimizer has to make educated guesses about the number of rows that will be returned. These guesses are based on patterns and statistical information, but they can be far from perfect. It's like trying to estimate the number of people attending a massive event by looking at a small sample of attendees. Sometimes, your estimate will be spot on, but other times, it will be way off the mark.
As a result, your SQL Server can choose suboptimal execution plans that lead to slow query performance. This is where the nightmare begins. You might find yourself scratching your head, wondering why a seemingly simple query is taking forever to complete. The culprit? Misplaced cardinality estimates.
⏳ The Perils of Outdated Statistics:
But wait, there's more to the cardinality estimation story. It's not just about the accuracy of estimates; it's also about the freshness of the data. Imagine trying to plan your week with a calendar from five years ago. Outdated statistics can have a similar effect on your SQL Server's understanding of your data.
Statistics become outdated over time as data distributions change. This can happen due to data inserts, updates, and deletes. If your statistics haven't been updated to reflect these changes, your cardinality estimates can be way off base.
Think of it like this: If your statistics are stuck in the past, your SQL Server is essentially making decisions based on outdated maps. It's like trying to find your way in a city that has completely transformed over the years. The roads have changed, new landmarks have emerged, but your GPS is stuck in 2016.
We'll explore the importance of keeping your statistics up-to-date and show you how to do it manually or automatically. This is a crucial step in preventing query performance nightmares caused by outdated information.
🤝 Join the Discussion:
We believe that learning is a collaborative journey. Your insights, experiences, and questions are invaluable to our community. So, as you watch this video, don't hesitate to share your thoughts and join the discussion in the comments section below. Let's learn and grow together as a community of data enthusiasts and SQL Server aficionados.
JBSWiki - Your Trusted Source for Data-Driven Excellence. 📊🔍
 0:05:57
0:05:57
 0:04:40
0:04:40
 0:07:39
0:07:39
 0:04:08
0:04:08
 0:00:21
0:00:21
 1:37:51
1:37:51
 4:03:27
4:03:27
 0:49:23
0:49:23
 0:12:00
0:12:00
 0:00:43
0:00:43
 0:00:06
0:00:06
 0:11:50
0:11:50
 0:00:39
0:00:39
 0:00:42
0:00:42
 0:08:22
0:08:22
 0:00:23
0:00:23
 0:00:37
0:00:37
 0:34:44
0:34:44
 0:00:14
0:00:14
 0:00:45
0:00:45
 0:00:55
0:00:55
 0:00:11
0:00:11
 0:00:50
0:00:50
 1:06:46
1:06:46