filmov
tv
Lesson A3 - Simulating Z80 functionality for the GBZ80

Показать описание
The Gameboy processor isn't a true Z80, and has many commands missing, however we can use macros to simulate the missing commands, so we can port Z80 code to the GBZ80 easily!
As always, this Video lesson matches the text lesson on my website, and you can get the source code as well...
If would like to support my channel and ongoing 8-bit game development, please consider backing me on patreon:
As always, this Video lesson matches the text lesson on my website, and you can get the source code as well...
If would like to support my channel and ongoing 8-bit game development, please consider backing me on patreon:
 0:25:24
0:25:24
Lesson A3 - Simulating Z80 functionality for the GBZ80
 0:37:26
0:37:26
Learn Z80 Assembly - With ChibiAkumas! - Lesson 1
 0:14:43
0:14:43
Learn Z80 Assembly Lesson A4 - Removing Self Modifying Code
 0:00:40
0:00:40
First z80 cpu test
 0:08:55
0:08:55
UAS MIKROPROSESOR Z80 Simulator
 0:16:12
0:16:12
GBZ80 Lesson S36 - Bitmap clipping on the GB/GBC via the tilemap
 0:12:35
0:12:35
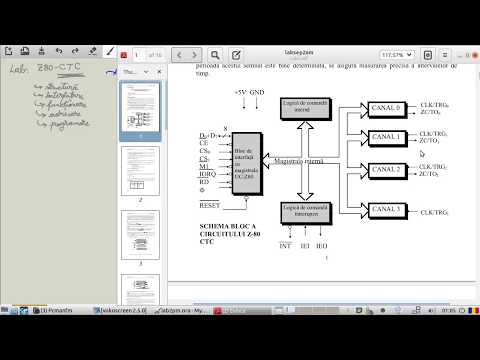
Endereçamento de periféricos Z80
 0:55:39
0:55:39
Cum programezi un microprocesor Z80 sa licare un LED
 0:26:19
0:26:19
Z80 Retro #7 - 512K Bank Selected Memory
 0:00:43
0:00:43
Human cell under microscope😯 || under microscope video 😮
 0:38:32
0:38:32
Z80 Retro #11 - Board Test Software Pt. I
 0:24:04
0:24:04
Computador Z80 com Servo Motor - PIO e CTC - Portas e Timers
 0:25:14
0:25:14
Homebrew Z80 Part One - An explanation of the schematic...
 0:10:05
0:10:05
DIY Z80 Retro Computer #5: Boot From CompactFlash Card
 0:03:17
0:03:17
Business Simulation
 0:05:45
0:05:45
Utilizando GCC para generar Ensamblador Mips32 para EasyASM
 1:04:21
1:04:21
No_3 Σειρά εκπαιδευτικών video με μικροεπεξεργαστές Πικ 6945850094...
 0:15:24
0:15:24
PROTEUS & PIC 16F84 - 16F628 - 16F877 PROJECTS 3
 0:01:13
0:01:13
Altairduino SPLIT PANEL operation.
 0:01:27
0:01:27
Spedi4You.de | How - TO | Fahrzeugauswahl
 0:32:16
0:32:16
IMSAI 8080 esp Demo with Desktop GUI, Email, Web Browsing and BBS access
 0:11:46
0:11:46
Elettronica digitale facile facile 07: I sommatori
 0:18:39
0:18:39
W65C265SXB: YM2149 Sound Chip Interface PCB (similar to AY-3-8910) for a Retro Homebrew Computer
 0:42:20
0:42:20
W65C265SXB: Planning Video, Sound, and Joystick Connections for Stackable Homebrew (65816, 6502)
Комментарии