filmov
tv
SQL Query Interview Questions - How to delete duplicates from a table? #sqlinterviewquestions

Показать описание
This video series discusses some most commonly asked scenario based SQL Query Interview questions.
In this video, we discuss the SQL query to delete/remove duplicates from a database table.
The sample dataset and SQL statements are available here -
Must Do Data Analytics Certifications -
Google Data Analytics Professional Certificate
Google Advanced Data Analytics Professional Certificate
Best SQL and Data Analytics Books -
Please do not forget to like, subscribe and share.
For enrolling and enquiries, please contact us at
In this video, we discuss the SQL query to delete/remove duplicates from a database table.
The sample dataset and SQL statements are available here -
Must Do Data Analytics Certifications -
Google Data Analytics Professional Certificate
Google Advanced Data Analytics Professional Certificate
Best SQL and Data Analytics Books -
Please do not forget to like, subscribe and share.
For enrolling and enquiries, please contact us at
 0:11:43
0:11:43
Top 9 SQL queries for interview | SQL Tutorial | Interview Question
 0:18:31
0:18:31
TOP 23 SQL INTERVIEW QUESTIONS & ANSWERS! (SQL Interview Tips + How to PASS an SQL interview!)
 0:36:33
0:36:33
Top 10 SQL Interview Queries | Popular SQL Queries for SQL Interview
 0:01:00
0:01:00
Data Analysis SQL Interview Questions | Running SUM | Who Hit the Sales Target First
 0:21:53
0:21:53
SQL interview questions and answers | Entry level data analyst interview
 0:00:23
0:00:23
SQL Query to Calculate The Difference Between Two Dates? SQL Interview Questions And Answers #SQL
 0:17:57
0:17:57
Part1: SQL Query Interview Questions & Answers
 0:20:14
0:20:14
IQ15: 6 SQL Query Interview Questions
 0:00:45
0:00:45
SQL Subqueries: The Ultimate Guide #shorts
 0:26:21
0:26:21
Top 25 SQL Interview Questions and Answers(The BEST SQL Interview Questions)
 1:06:51
1:06:51
Top SQL Queries for Interviews Questions and Answers | SQL Training | Intellipaat
 0:00:13
0:00:13
SQL interview question | Challenge yourself | SoftwaretestingbyMKT | Interview Preparation on SQL
 0:37:22
0:37:22
Solving SQL Interview Queries | Tricky SQL Interview Queries
 0:00:55
0:00:55
Data Analyst SQL Interview Question |Self-Joins Explained #dataanalysis #sql #sqlinterview
 0:00:49
0:00:49
SQL Interview Question: Find the Last Record in a Table (SOLVED!)
 0:00:55
0:00:55
SQL Server Interview Questions and Answers :- What to prepare ?
 0:00:18
0:00:18
81 Find second highest salary from employee table using SQL? #interviewquestions #javaprogramming
 0:00:33
0:00:33
5 Best SQL Websites to Practice n Learn Interview Questions for FREE
 0:24:29
0:24:29
15 SQL Interview Questions TO GET YOU HIRED in 2025 | SQL Interview Questions & Answers |Intelli...
 0:05:02
0:05:02
SOLVE 5 SQL QUERIES IN 5 MINUTES (PART 1) | MASTER IN SQL | SQL INTERVIEW QUESTIONS
 0:17:40
0:17:40
Learn Basic SQL in 15 Minutes | Business Intelligence For Beginners | SQL Tutorial For Beginners 1/3
 0:00:10
0:00:10
KPMG SQL Interview question on Joins.
 0:00:58
0:00:58
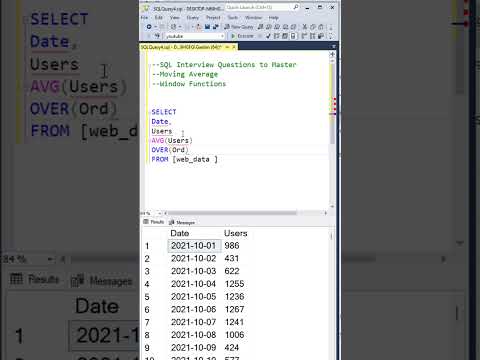
Data Analyst SQL Interview Question | Window Functions | Moving Average #sqlinterview #dataanalysis
 0:01:00
0:01:00
Amazon SQL Interview Question | Subquery VS. CTE | 2 Solutions
Комментарии